阅读:0
听报道
量子计算是一种全新的计算范式,有望为人类提供超乎想象的计算能力,从而为各个领域乃至我们日常生活带来极其深远的影响。随着一些科技企业巨头的加入,人们似乎能感觉到量子计算机已经距离我们不远了。本文试着回答如下几个问题:什么是量子计算?量子计算能干什么?如何实现量子计算?如何用超导体来做量子计算机?我们距离通用量子计算机还有多远?希望读者们读完之后,能够对量子计算有一个正确的认识,合理的期待!
撰文 | 无邪
1 我们的感官是牛顿力学的,我们的世界却是量子的
人类大约从6万年前开始认识这个世界:通过眼耳鼻舌身来感知,然后在大脑中建立模型,以便于我们能够适应这个复杂而险恶的星球,世世代代繁衍下来。
我们身体自然进化出来感官,比如眼睛、耳朵,都是感知宏观物体的,所以当三百多年前牛顿发现力学三定律和万有引力定律之后,人们变得雄心万丈,以为已经找到了撬动地球的那个支点。直到一百多年前物理大厦的两朵乌云出现,我们才终于慢慢意识到,现实世界底层其实是量子的。而量子现象是违反我们的常识的。
又经过了一百年,我们对量子操控和测量技术越来约娴熟,终于,科学家们发出了世纪之问:假如量子世界由我做主,我们能做哪些原本不可能的事情呢?——用量子来做计算,就是其中最大胆的一个想法之一。

2 什么是量子计算?
我们现在使用的电脑、手机和平板等等,最底层的芯片都是由半导体晶体管组成的01电路上。在逻辑上,我们将这种有0和1两种状态并且可以在这两种状态之间互相转换的单元称之为比特。而为了区别于我们马上要讲的量子比特,我们姑且称它们为“经典比特”。现在计算机上运行的所有程序,都是建立在大量的经典比特之上,按照一定的顺序进行各种逻辑门操作,然后给出最终的结果。了解了经典计算的基本运行原理之后,理解量子计算就不难了。所谓量子计算,就是把经典比特换成量子比特,把经典的逻辑门换成量子的逻辑门,把经典的测量换成量子的测量。当然还要把经典的算法换成量子的算法。在这样一套基于量子力学基本原理的新体系上产生出来的计算方法,就是量子计算了。
量子比特
量子比特是一个量子的二能级系统,与经典比特相比,它有两个显著的差别。首先,一个经典的比特,能够表示的状态数只有两个,0或者1。而一个量子的比特,由于量子态可以处于叠加态,因此它实际上可以表示无穷多个状态。我们可以把这些状态映射到一个半径为1的球面上,球面上的任何一个点,都代表一种可能存在的状态。这个球被称作“Bloch球”,为了致敬第一个发明核磁共振技术的物理学家布洛赫(Felix Bloch,1905-1983)。
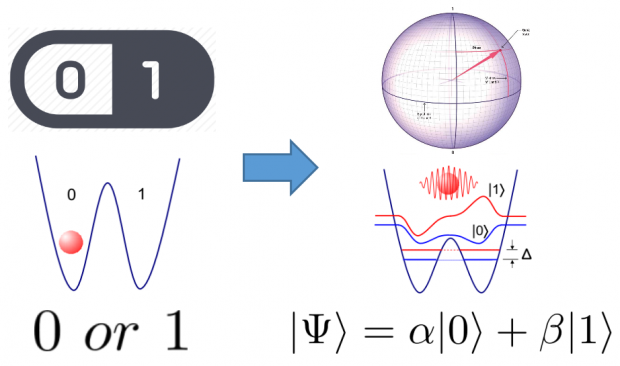
经典比特(左) vs 量子比特(右)
纠缠
上面讲的是单个量子比特和经典比特的区别。如果是很多的比特,它们还有一个重要区别,就是量子可以纠缠在一起。纠缠是一种特别神奇的量子现象,它说的是多个量子系统组成的复合系统可以处在某种“量子关联”态。在这些状态下,单看每个粒子我们得不到任何信息,必须把它们合起来看才能获得其中的信息。曾经有人打过一个比方:如果是一本经典的书,我们都知道该怎么读,那就是逐句逐页地读完,我们自然就知道里面讲的是什么了。但如果这本书是量子的,那情况就大不相同,你翻开每一页看,上面都是乱码,只有把整本书合起来看,你才发现故事藏在书页之间的关联之中。

为了完整描述一个多粒子纠缠态,我们需要在一个很高维度的希尔伯特空间中来表示它们,这个空间的维度随比特数增加而指数增加。例如,要表示两粒子纠缠态,我们需要4个参数(就像坐标)来描述;而要表示3个粒子的纠缠态,我们就需要8个参数;4粒子纠缠态需要16个;5粒子,抱歉已经有点写不下了……

量子比特张开的编码空间随着数量而指数增加
如果粒子数继续增加,它的状态空间会呈指数增长。这是一个相当可怕的数字,如果N达到50,状态空间的数量将达到现在一台超级计算机每秒的运算次数,而当N达到300时,这个数字将超过宇宙中所有原子数的总和。
这就是指数的威力。爱因斯坦曾经说过,这个世界上最强大的武器,不是原子弹,而是复利加时间。有一个经典的故事,当年印第安人将曼哈顿岛以24美元的价格卖给了一个美国人,过了三百多年之后,曼哈顿岛成了纽约最著名的商业区,价值超过千亿美元。但如果这些印第安人当时把这笔钱存银行的话,过三百多年,他们不仅可以把曼哈顿重新买回来,而且还能剩下一大笔钱!
还有一个很有名的故事,讲的是一个印度国王因为非常喜欢国际象棋而承诺要给国际象棋的发明人奖励。这位智者提出只要在棋盘的第一格放1粒麦子,第二格放2粒,第三格4粒,以此类推,放满整个棋盘就行。国王满口答应,实际上一放才知道,这是一个天文数字,他最终需要拿出922亿亿颗麦子,以当时印度的粮食产量来算,即便再过三百年,可怜的国王也付不起这个奖励。这就是指数的灾难。我们现实生活中有很多这类指数灾难性问题,比如相互作用的多体问题、互联网路由问题、气象预测、大脑神经结构等等。这些问题,即便我们完全知道方程的形式和所有参数,我们也无法精确求解,因为太复杂了。量子比特纠缠构成的体系正好能够提供一个指数级增长的编码空间,那我们是不是可以利用这种特性,来解决这些指数级复杂的问题呢?


答案是肯定的。最早提出用量子体系来计算,或者说模拟量子物理问题的科学家是费曼,不过当时只是一个概念。真正从数学上证明有效的算法,是20世纪90年代数学家提出的两类著名算法:Shor算法和Grover算法。Shor算法表明,用量子的逻辑电路,可以将大数分解问题的求解时间从指数级降低为准多项式级。大数不可分正是现在互联网上应用最广泛的非对称加密系统,也叫公钥加密系统的数学基础。有人估算过,用现在最好的算法破解2048位数的公钥密码,需要超过100万年时间,而用Shor算法只需要几分钟。
Grover算法是一个搜索算法,它可以将无结构的数据搜索问题从N复杂度降低为根号N复杂度。虽然加速能力不如Shor算法,但搜索算法是一种非常基础的算法,可以映射到多种实际问题中去。当N非常大时,这种加速效应也非常显著。目前互联网中每时每刻产生的海量数据,要从中寻找有用信息,正对应着这种N非常大的情况。此外,搜索算法还可以用来进行密码破解。
除了这两类算法以外,量子计算还可以通过模拟复杂系统的哈密顿量来进行量子化学计算,研究原来很难研究的复杂多体物理问题;通过量子纠缠特性,量子计算还可以快速计算多参量的代价函数,从而提高优化问题的求解效率,在人工智能方面也有潜在的应用价值。

量子计算并不是无所不能的!
这里给出一个计算问题的集合图,在计算科学中,所有的计算问题可以分为可判定问题和不可判定问题。
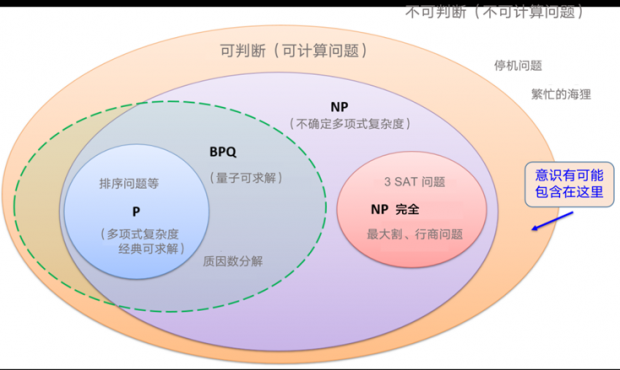
计算机能够解决的只是可判定类问题,也就是可计算问题。这其中有三个重要的大类。一类是P问题,这类问题可用图灵机在多项式复杂度内解决,因此是传统计算机就能够高效计算的,比如排序问题。第二类是NP问题,属于不确定多项式复杂度问题,这些问题好验证,但未必好求解。P问题包含于NP问题,而量子计算就是要解决那些P以外的计算问题,比如Shor算法对应的质因数分解。NP问题中还有一类NP完全问题,这些问题的计算复杂度是指数增长的,其中包括非常经典的最大割问题、行商问题等等。如上图所示,量子计算目前来看是无法高效地解决这些问题的。所以,量子计算很可能并不能高效地解决所有问题。但是,无论如何,这种新的计算范式,可以大幅拓展现有的计算能力,使得我们可以解决更多、更复杂的问题。
3 如何实现量子计算?
如果我们知道量子计算是如此的令人期待,那么下面进入第二个问题:如何去实现量子计算呢?
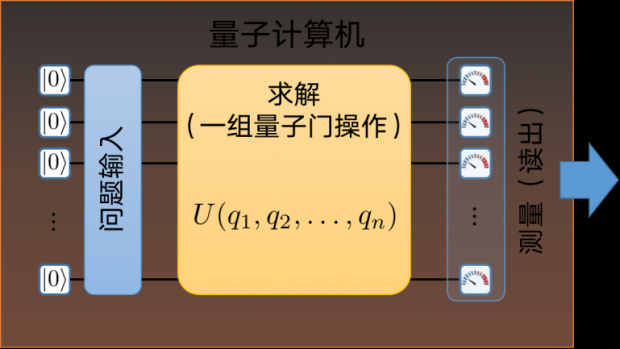
从数学上讲,量子计算可以分为如下几个步骤:首先我们要有一组完美的量子比特,并且能够将他们初始化,比如全部初始化到基态;然后将问题的初始条件编码到这些比特中去;接下来就是执行算法的部分,它对应于一组量子门操作,可以写成一个总的幺正矩阵U;执行完算法之后,便要对所有的量子比特进行测量,得到最终的计算结果。
需要注意的是,由于量子测量引起的量子态塌缩是完全随机的,所以上面的过程必须要重复N(N远大于1)次,才能够准确获得末态0和1的分布情况。比如说,谷歌的“量子霸权”实验,中间的U就是一组随机选取的量子门,它执行了一百万次,才得到最终的结果。当然了,100万次听起来非常之多,但对于量子处理器而言,它执行一次所需要的时间只有200微秒,而且其中绝大部分时间其实是在等待,等量子比特“冷却”下来,所以总的执行时间也只有200秒而已。同样的计算,用超级计算机模拟却需要上万年的时间。最近我国的科学家张潘利用张量网络方法,将这一模拟时间缩短到了5天,而且只用到了60个GPU组成的集群,可见“量子霸权”也是相对的。
物理上要去做量子计算,就是一件非常富有挑战的事情了。因为实际的物理系统,不可能像数学模型那样完美无缺,它们会受到噪声的影响,会受到各种物理条件的制约。更何况我们还要对极其脆弱的量子态做操控和测量。这就是为什么量子计算的理论和算法研究早在上世纪八九十年代就出现了,而实验物理研究却一直到2000年以后才逐渐走上快车道。
现实世界中,能够用来做量子计算的体系有很多,包括自然原子、离子阱、光子、二维电子气、NV-色心、核自旋、冷原子,以及超导量子比特,等等。这些物理的量子体系差异很大,某些体系,比如自然原子、离子阱和光子等,它们在室温下就能够保持很好的量子相干性。超导量子比特和基于二维电子气的量子点则必须在接近绝对零度的极低温才能保持较好的量子相干性。然而,好的量子相干性并不是成为一个好的量子比特的唯一判据。下面就讲一下,要成为一款优秀的“量子比特”,并成功构建出实用的量子计算机,需要具备那些要素。
这就是2000年由IBM的一位科学家Divincenzo提出来的五条准则。我们就叫它“Divincenzo准则”。我们来一条条看:
首先,我们必须要能够构建一组,注意不是一个两个,而是能够扩展的大量量子比特,并且能够很好的表征它们,确定它们的哈密顿量。这一点其实就排除了很多候选者,比如核磁共振系统和NV-色心。它们虽然有足够的相干性,能够很好的操控,但是却无法扩展。
第二条是必须能够对这组量子比特进行初始化,比如将所有量子比特置于基态。这点是不言而喻的,如果初始状态都无法确定,结果肯定是不确定的。
第三条是量子比特必须具有足够长的退相干时间。一般来说,这个时间必须远大于执行完量子门操作所需要的时间。否则等量子算法执行完,这些量子比特已经退相干了,测到的就几乎全部是噪声,结果就没有意义了。
第四点,就是必须能实现一组通用的量子门操作,包括CNOT门、C-相位门以及各种单比特门等,这是执行逻辑运算所必须的。这其中最关键的就是两比特门,也叫纠缠门,因为只有单比特门的量子计算机是很容易被经典计算机模拟的,起不到量子加速的作用。
最后一点:必须能够很好地测量这些量子比特的最终状态。这也是显而易见的,测不了就不可能得到运算结果。
同时满足这五个条件的真实物理系统,就非常少了。基于超导量子比特的超导量子计算,就因为在这五点上都能够做得很好,最终脱颖而出,成为现在各大头部公司最看好的技术方案。下面就看看这种量子比特到底好在哪。
4 如何用超导体来实现量子计算?
超导现象从发现至今已经有超过百年的历史了(参见《百年超导路,今朝抵室温》),这是一种非常罕见的、具有非常陡峭转变而且很robust的物理现象。BCS理论告诉我们,超导是由于所有传导电子在低温下以库珀对的形式集体凝聚到基态而引起的相变。这一相变导致费米能附近打开了一个能隙,任何低于这个能隙的低能过程都无法对电子系统产生有效的激发,从而为各种低能的量子行为提供了绝佳的保护。
超导态是一种典型的宏观量子现象,因为参与超导电性的粒子是宏观量级的库珀对高度重叠而形成的集体行为。这种宏观量子性,为超导量子比特奠定了易于耦合、易于操控也易于读取的先天条件。但是,要做量子计算,只有超导性是不够的。大块超导体的波函数相位是恒定的,粒子数也趋于无穷,没办法提供量子比特所需要的能级分立性和非线性。因此,我们必须想办法,对超导体做额外的约束。

这就要讲到超导量子比特的关键器件——约瑟夫森结(参见《量子计算背后的硬核技术:约瑟夫森参量放大器》)。一个约瑟夫森结是由两块超导体中间夹一层非常薄的绝缘层构成的结型器件。左右两边的超导体有各自的相位,中间的绝缘层将它们分隔开,但由于量子隧穿效应,两边超导体中的库伯珀对,都有很小的概率穿过这个绝缘层到达另外一侧。这种隧穿,就使得两边超导波函数形成一定的干涉效应,带来一些很奇特的性质,主要体现在两个方面:我们分别称之为约瑟夫森电流关系和电压关系,在电子学上往往也叫作直流约瑟夫森效应和交流约瑟夫森效应。
约瑟夫森电流关系告诉我们,可以有超导电流流过约瑟夫森结,这个电流大小是随两边超导体相位差ᶲ(有时候也用ᵟ来表示)而正弦变化的,最大不能超过Ic,也就是临界电流。约瑟夫森电压关系则是说,这个相位差的变化率是与电压成正比的。很显然,这个器件的电路特性是非线性的,因为电流关系式中出现了正弦函数。这种非线性会导致很多奇异的性质,比如约瑟夫森振荡,在这里我们只关注它作为一个非线性且无损的电路元件的性质。上面两个式子合起来看,我们发现约瑟夫森结的行为很像一个电感,但它的电感值不是固定的,而是随结上的相位差而变化。我们可以把一个约瑟夫森结的相位看成是一个在“搓衣板势”中运动的粒子,在每个坑里面,粒子会左右振荡;在量子区域,也就是温度足够低的时候,这种振荡是量子化的,并且由于电感的非线性,这些能级间距是不一样的,这就是我们前面所说的非线性。
看,到这里,我们发现,由两块超导体构成的约瑟夫森结,能够提供能级的分立性和非线性。但是,光有约瑟夫森结依然是不够的。因为它自身携带的电容和电感参数往往用起来不合适,要想得到一个很趁手的量子比特,我们还需要加入一定量的常规电容和电感。
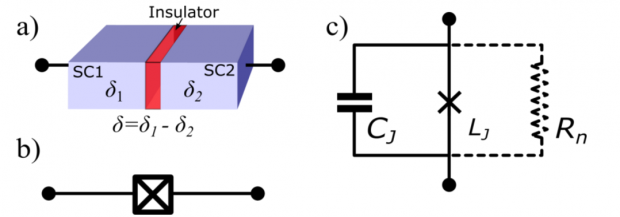
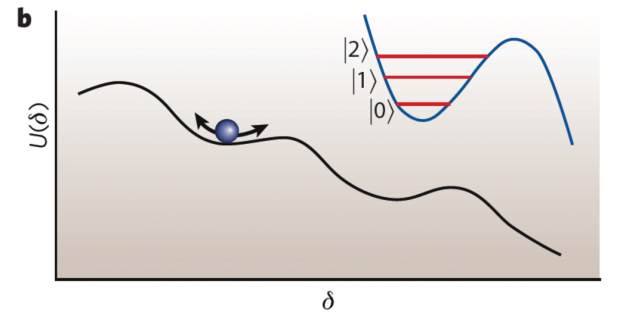
a)超导约瑟夫森结;b)约瑟夫森结在电路中的表示;c)约瑟夫森结的电路模型(RSJ模型);下图为约瑟夫森势能随相位的变化。相位可以看成一个在势能曲线上滚动的粒子。在其中一个势阱(势能极小值附近)内,会形成分立的能级,不同能级之间的跃迁对应不同的相位振荡频率。利用这种非线性能级系统中最低的两个能级,就可以构造一个量子比特。
因此,现在大家常用的、适合于做量子计算的量子比特,实际上是由约瑟夫森结以及一定的电容或电感共同组成的电路。它们结合在一起,会形成非常复杂的超精细能级结构,不过作为量子比特,我们只需要用其中能量最低的两个能级就行了,也就是基态和第一激发态。从上世纪末第一个超导量子比特出现以来,经历了二十来年的发展,已经产生了很多种超导量子比特,它们有各种各样的名字。不过万变不离其宗,它们其实就是调整电路中的电容、电感、约瑟夫森结电感、环路磁通等参数,从而构建出不同的能级结构。
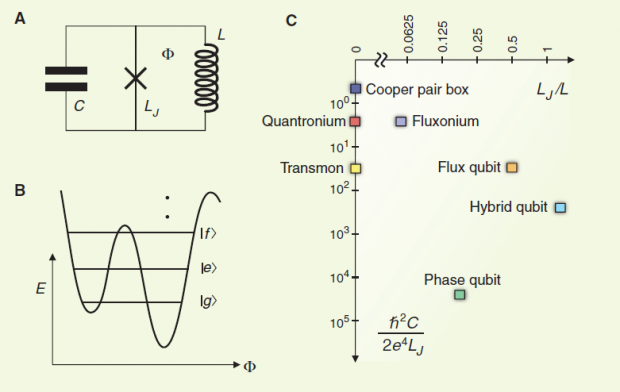
A)超导量子比特的通用等效电路;B)典型能级结构;C)已经发展出的多种超导量子比特在参数空间中的分布情况。
根据参数选取的不同,早期的超导量子比特大致可以分为三类:电荷量子比特,也叫库珀对盒子,磁通量子比特和相位量子比特。这三种量子比特,都受不同噪声的困扰而导致退相干时间很短。经过大量的研究,物理学家终于搞清楚这几种噪声来源,主要包括电荷涨落,磁通涨落,以及准粒子噪声等。搞清楚噪声来源之后,就可以想办法去压制这些噪声,从而大幅提升退相干时间了。
现在最为流行的Transmon或Xmon量子比特,就是通过压制电荷量子比特中的电荷涨落而大幅提升退相干时间的典型案例。Tansmon的全称是“传输线旁路的等离子体振荡量子比特”。读起来很拗口,其实就是在电荷量子比特上增加了一个大的旁路电容。这个电容的加入,极大地平滑了电荷色散关系,也就是说,现在系统的能量对电荷的涨落变得很不敏感,自然就抑制了电荷噪声。当然这也是有代价的——系统的非线性大幅下降了。不过,相比退相干时间带来的好处而言,这种下降是可容忍的。Transmon还有一个重大的创新点就是把原来用于调控量子比特的门电容换成了与一个传输线谐振腔色散耦合。这一设计为量子比特提供了一种非常有用的测量方式——“量子非破坏测量”,这种测量对于量子纠错而言是非常关键的。这里不展开来讲了。(关于量子纠错可参见《量子计算的下一个超级大挑战》)
Xmon实际上就是把Transmon中的一个电容极板换成了地,本质上与Transmon是相同的。Xmon很便于扩展,Martinis的团队首创Xmon结构集成了5个量子比特,很快就吸引了Google量子AI团队的注意,随后整个团队就加入了Google,然后几年后就有了“量子霸权”之伟业。
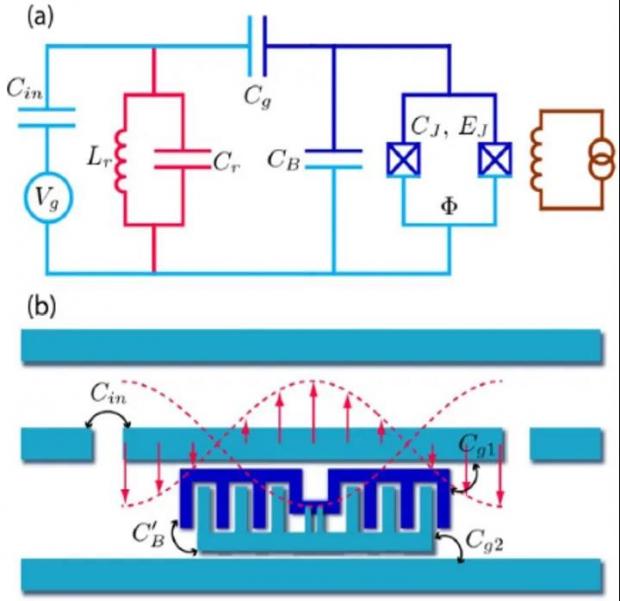
目前最流行的transmon/Xmon量子比特。
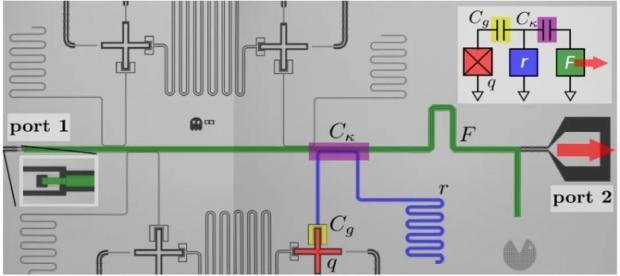
一个多比特超导量子芯片的照片,图中用不同色彩标出了不同的电路元素,包括量子比特、读出谐振腔、读出总线传输线等。
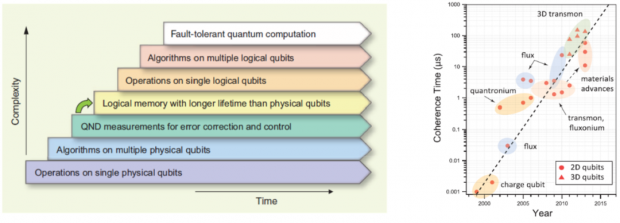
前面讲到超导量子比特经过多年的发展,发展出了多种结构。其实在这一过程中,科学家也逐步解决了扩展性、退相干、门操控和读出等方面的问题,也就是前面Devincenzo准则中提到必须解决的问题。2013年,两位著名的量子计算专家,Yale大学教授Devoret和Schoelkopf写了一篇展望,给出了通用量子计算发展的一个路线图,其中超导量子计算已经处在第三到第四阶段发展的水平,而其他很多方案,仍处于第一或第二阶段。同年,MIT的研究组画了一张图,显示了超导量子比特退相干时间的“摩尔定律”,从最早第一个量子比特不到3纳秒,提高到了现在300微秒的水平。不到二十年的时间,提高了五个数量级,可见这个领域的发展速度之快。现在,几个著名的科技公司,包括Google、IBM、Intel等,都参加到了量子计算研发的行列中来,而他们都选择的是超导的方案,可以说,超导量子计算,已经成为目前最有前景的量子计算实现方案之一!
5 量子计算离我们还有多远?
2019年10月,Google在Science上刊出了一篇论文,介绍了他们验证了量子霸权的实验结果。这个实验让全世界都备感兴奋,谷歌的CEO皮查伊评价这个实验的意义,就像当年莱特兄弟发明了第一驾飞机。不过,正如第一驾民用客机要到50多年后才诞生,量子计算机走入千家万户,仍有很长的路要走。
我找了张珠峰的照片来做比喻。如果把建造通用量子计算机比做珠峰的峰顶,那么,在登顶之前,我们还有两座大山需要翻越。首先是构建出量子纠错的逻辑量子比特,然后是在逻辑量子比特上实现所有的通用量子门操作。在这两座大山面前,量子霸权其实只是一个小土坡而已。不过也不要小看这个小土坡,它的海拔,其实也在五千米以上了。

我们再来看一张更为量化的图。
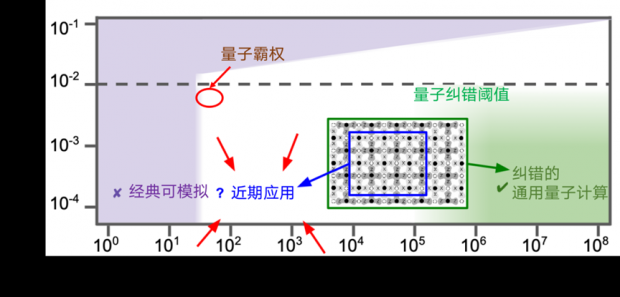
图上的绿色区域是纠错的通用量子计算机所需要达到的硬件要求。虚线是进行表面编码量子纠错的错误率阈值,我们刚刚超过了这个阈值;大约50个量子比特以内的量子线路是经典计算机就能够模拟的,我们也刚刚超过了这个阈值。那距离通用量子计算机还差多远呢?单从比特数量上看,我们还有5个数量级以上的差距。或许很多人对这个差距有多大一下子没什么概念,那我们就以过去半导体晶体管的集成速度来做个估算。著名的摩尔定律表明,几十年来,晶体管的数量一直以大约每两年翻一翻的速度在增长。如果把这个规律套用到量子比特数量的发展上,那么,要增长5个数量级需要多久呢?需要26年(我掐指一算,那年我正好退休)。那是不是我们可以对量子计算继续抱观望态度呢?也不是。在50个到100万个的巨大空档里面,我们依然是可以做很多事情的。现在,学术界和工业界都在积极的寻找近期应用,看看如何在中等规模有噪声的量子计算机上,开发出有实际经济效益的应用来。比如最近Google就在实现量子霸权的芯片上,模拟了一些简单分子的基态求解问题,探索利用量子芯片来加速化学分子计算的可能。他们甚至开始与制药厂合作,探索如何利用量子计算来加速新药的研发。
6 结语
在技术上,我们不仅要不断克服量子比特数量增长带来的各种问题,还需要不断去提高每个量子比特的退相干时间和操控的保真度。也就是说,量子资源实际上是要从两个维度上来拓展的,前一个我们可以说是空间上的,后一个则是时间上的。我们需要不断解决比特数增加带来的排线问题,以及串扰的问题。Google在Sycamore芯片上,就应用了倒装焊技术成功的解决了二维阵列排列的量子比特排线问题。另外,微波的引线和封装也是一个很大的难题,因为量子比特操控和读取都需要微波,但现在的微波器件体积都很大,在极低温下做大规模封装几乎是不可能的,必须要想办法将微波线路小型化,甚至某些微波器件要直接做到芯片上去。此外,电子学的集成扩展,跨芯片间的量子态传输和纠缠等技术,都非常具有挑战性。
困难很大,但是希望也很大。乐观派认为量子计算机的发展速度要比我刚才的估计要快得多,比如谷歌就已经给出了他们的十年发展路线规划图。目前他们已经实现了第一个小目标量子霸权了,到2029年,他们计划将做出超过100万个量子比特,而且是量子纠错的量子计算机。而在中间的这段时间,他们将不断探索中等规模有噪声量子计算机上的应用,包括量子模拟、优化、采样、量子人工智能等等。也就是说,或许在三到五年的时间上,量子计算就已经开始改变我们的生产和生活方式了。当然,这只是比较乐观的估计,但不管怎么样,量子计算蕴含着无限可能,正等待着我们去开发!
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}