阅读:0
听报道
Google 提“量子霸权”,IBM 提“量子优势”,这两种提法说的是一个意思吗?量子优势与量子霸权相比,到底哪个更激进?它们将如何影响科技界、工业界和我们的未来?今天的文章就是关于量子霸权与量子优势的一篇专业又有趣的科普。
撰文 | 无邪(量子计算领域研究人员)
两个大佬级的科技公司正在全力推进量子计算机的研发,Google提“量子霸权(quantum supremacy)”,IBM提“量子优势(quantum advantage)”,这两种提法是一个意思吗?量子霸权给人感觉就很霸道啊,是不是量子霸权就比量子优势更为激进呢?在这两个概念提出之初,笔者也感觉量子优势是更为温和的,但随着理解的逐步加深,现在有了不一样的看法。借着Google最近声称的量子霸权的横空出世(这一提法尚有争议。据最新消息,IBM在其10月21日发表的预印本论文中对Google经典计算机模拟部分做了新的评估。参见后记),笔者在此谈谈个人见解,欢迎方家指教。
1 Google与“量子霸权”
9月底,Google 量子 AI 团队通过 NASA STI program 发布了一份报告,题为“采用一个可编程超导处理器实现量子霸权”。文中报道了一个包含53个量子比特的量子芯片,在态空间随机采样算法上,对一个实例执行100万次需要约200秒,而对于同样的任务,要达到同样的保真度,采用目前最强的超级计算机大约需要一万年。

这块芯片的代号叫“Sycamore”,用一种美国的悬铃木(有点像法国梧桐)来命名,芯片上还印了一片悬铃木叶似的 logo。这也是Google量子计算芯片的命名特色,比如他们正在测试中的另一块包含72个量子比特的芯片则命名为“Bristlecone”,以狐尾松来命名,芯片上则印着一个松果。无论是悬铃木还是狐尾松,都用上了最新的封装技术——倒装焊,这一技术使得对量子比特进行二维矩阵式排列成为可能,而这种近邻耦合的矩阵排列形式是进行表面编码量子纠错所必要的。由此可以推断Google有可能在不久的将来测试真正意义上的量子纠错,不过“量子霸权”更符合现阶段的发展需要。
悬铃木看起来只有53个量子比特,但事实上它包含了142个!只是其中88个量子比特仅作为耦合器工作,另外54个(哦!抱歉,坏了一个)作为全功能的量子比特使用。尽管坏掉一个,53个量子比特也足以演示“量子霸权”了,它的态空间(指53个量子比特组成的量子系统所有可能存在的量子态的集合)维度高达253,有兴趣的同学可以算一算这是多大的一个数。如果能够全部用上,现有的超级计算机别说计算了,就是存储这个态(存储消耗的是空间,由于53个量子比特的纠缠态过于复杂,需要消耗极大的内存空间)就够喝上好几壶了。

Google团队对芯片做了全面的基准测试,结果表明总体的单比特量子门和双比特量子门操作保真度都能够达到99%以上,已经基本达到了能够进行表面编码纠错的阈值。在更多的细节中,团队还指出,这些量子门操作的错误率中,主要成分是离散的、局域的泡利错误(一个量子比特发生了比特翻转或相位翻转),这就意味着这些错误都是可以用量子纠错算法来消除的。对于未来的量子纠错而言,这无疑是一个好消息。
2 量子纠错有多重要?
说到量子纠错,也许很多人并不能立刻感受到其重要意义。在现有技术下,所有的量子比特或多或少都是存在噪声干扰的,我们将这种有噪声的量子计算单元称之为“物理比特”。但是,要实现一些有用的量子算法,比如著名的 Shor 算法(就是那个那个……能破解密码的那个),对错误率的要求高得多,直接用物理比特是不可能的。
那怎么办呢?唯一的办法就是利用量子纠错,用一大堆有噪声的物理比特,通过适当的编码形式,来表示一个比特的信息。我们把这种量子比特称之为“逻辑量子比特”。将信息编码到更大的空间中去以确保信息不易丢失是通信中最常用的手段,比方说两个人打电话,电话线上有噪音导致听到的声音断断续续,要想确保对方听到,我们常常会说:“对对对对对,对对对对对,就是它,就是它,对的,是的……”这样即便对方漏听了几个对,还是会听到不少的对,然后就能确认是对了。
比较麻烦的是,量子世界与经典世界还有一个重大的区别:观测会导致量子态发生非幺正演化,迫使量子态投影到某一个与观测相关的算子的本征态上去。说人话就是,如果我们直接去看一个量子比特,这个量子比特的状态就会发生改变,最终展现给我们的不会是它原来的样子。更可恨的是,这种改变是不可逆的,看过之后就再也回不去了——某些信息彻底丢失了。
所以我们显然不能这样进行量子纠错。好在我们可以将一个量子比特与很多其他量子比特纠缠起来,然后只去看那些不包含信息的比特。在这种情况下,尽管测量得不到信息,但测量结果可以指示奇偶性的变化,从而给出“错误症候”,就像中医的“望闻问切”,一旦发现印堂发黑,就知道病入心肺,赶紧开药治病救人。正因为测量不获取信息,所以也就不破坏信息,但我们却得到了错误症候,知道是哪个比特出错了,也就知道怎么纠错了。这就是量子纠错的基本思路。
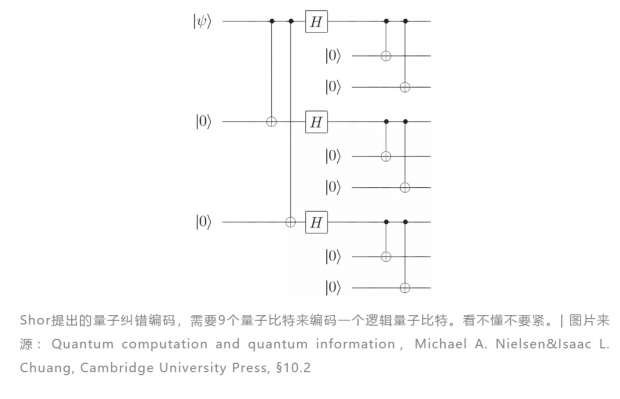
量子纠错的编码方式有很多种,但不管什么样的方案,对单个物理比特的错误率都有一个基本要求。早年的编码方案,如CSS码、Shor编码等,对物理比特错误率的要求仍非常之高(大约为10-6,即一百万次中错一次),目前最好的物理量子比特距离这个要求还有两个数量级之差。
后来 Alexei Kitaev 提出了基于拓扑方法的表面编码[1],这一编码形式采用二维矩阵形式排列量子比特,比特之间只需要近邻耦合,它对错误率的阈值要求大约是0.75%,一千次里错7次就满足要求。这极大地降低了技术要求,现有的实验方案,比如超导量子电路已经达到了这一阈值要求,量子纠错在技术上成为了可能。不过,表面编码是有代价的——它需要极高的开销。以Google的量子比特为例,目前的技术水平,如果想达到求解Shor算法的要求,需要约3600个物理比特来编码一个逻辑比特。想想现在才刚刚超过50个,这个要求也是相当高的。当然,还有很多其他很有潜力的编码形式,比如耶鲁大学主推的玻色编码方案,鉴于其偏离主题,在这里就不展开来讲了。
注释 [1]:最早Kitaev的方法是环面码,后来发现环面几何结构不是必须的,于是Bravyi和Kitaev进一步发展为表面码,Freedman和Meyer也给出了一种平面码并证明这两种码是同构的。
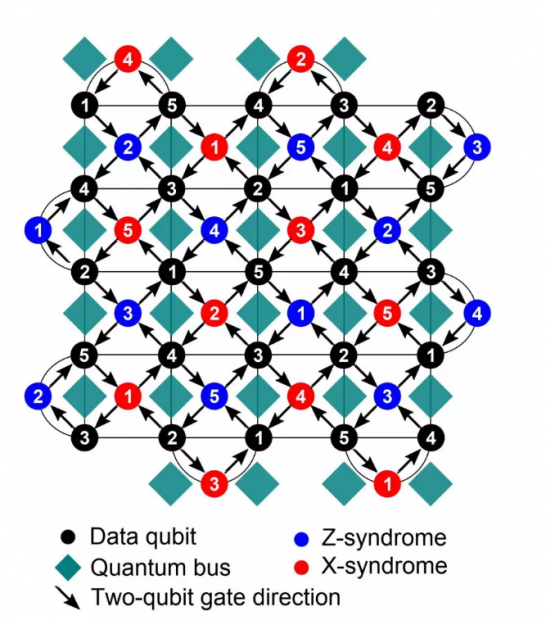
表面编码,量子比特像棋盘一样矩阵排列。黑色圆点是存储了信息的量子比特,蓝色圆点和红色圆点则是附属的用于纠错的量子比特,分别用于探测比特翻转错误和相位翻转错误。这种编码形式只需要近邻耦合(图中的绿色菱形块)| 图片来源:Building logical qubits in a superconducting quantum computing system, npj Quantum Information, DOI: 10.1038/s41534-016-0004-0
3 量子霸权:展示量子计算的潜力
回到量子霸权。Google采用了一种随机量子电路来展示量子计算的潜力。所谓随机量子电路,就是在一个量子门的集合中随机挑选一系列的门,作用在随机挑选的量子比特上(对于两比特门,则随机与它四个近邻的比特之间进行),最终的输出是253维的态空间上的一个随机取样(这个说法很绕,说白了就是我不管输出结果是什么,总之是那么多种可能状态的其中一种)。
Google团队最多做到53个量子比特,1113个单比特门,430个双比特门,整个算法的周期数[2]最大到m=20。作为对比,Google在德国于利希研究中心超算、目前世界上排名第一的超算Summit,以及Google云计算服务器上进行了模拟。当m=20时,因为内存不足,计算机已经无法模拟。当m=14时,进行三百万次采样,保真度达到1%需要的运行时间测算下来为1年。当m=20,达到0.1%保真度所需要的运行时间估计要达到1万年!更令人吃惊的数据是,做这个运算需要50万亿核时,需消耗1千兆度的电力(我想这还没计入给计算机散热的空调用电)!把整个Google卖掉才有望完成一次这样的计算。
注释 [2]:为了精确地执行量子算法,我们将量子门操作限定在一个个固定时长的时间段内,每个时间段就称之为一个周期cycle。

值得注意的是,量子计算机的运算能力是双指数加速的,这就是所谓的内文定律(Hartmut Neven是Google量子AI的头,这个定律是以他的名字命名的)。量子比特数与算法深度(指能够有效执行的门操作层数,算法深度与错误率成反比)将随时间指数增长,而量子计算能力又随之指数增长(第一个指数类似于摩尔定律,是技术发展的速度,而第二个指数是相对于经典计算而言的,量子系统提供的态空间维度随比特数呈指数增长,因而其组成的纠缠系统复杂度也将呈指数增长,带来的计算潜能也随之指数增长)。这将是一个无比恐怖的增速!以这种增速发展的话,经典计算机显然是望尘莫及的。
另一个需要注意的地方是:Google用来演示量子霸权的算法是毫无意义的,它不解决,也压根不打算解决任何问题。它的目的是为了展示量子计算的潜力。我们需要保持清醒的是,量子霸权演示中用到的还是有噪声的物理比特,距离用于解决真正意义上的计算问题还有很长的路要走。

4 量子优势:催生商业价值
几乎是同时,IBM也向外界发出声音:他们近期会推出53个量子比特的量子云计算服务。时间上和数量上都如此接近,令人不禁遐想。对于量子霸权,IBM声称他们一直致力于实现“量子优势”:针对真实的应用场景,展现出量子计算超越经典计算的能力。注意这里的“真实应用场景”几个字,言下之意就是,量子优势不仅要体现出计算能力的碾压,还得是有用的。换句话说,量子优势的实现,将能够催生出商业价值来。对于一个追求利益而非理想情怀的公司而言,这显然是他们做这件事的原始驱动力。
今年3月份,IBM在《自然》杂志上发表了一篇关于量子机器学习的论文,提出两种用于机器学习的量子算法,利用多量子比特系统超大的态空间作为机器学习的特征空间,实现量子的变分分类器,以及估算核函数。这两种方法有望在实验上演示并实现“量子优势”。与Google的内文定律类似的,IBM在其博客上发文提出量子时代的摩尔定律:量子体积将以每年翻一倍的速度增长。以这一增长速度,IBM预计将在2020年代实现量子优势。在这里,IBM定义了一个“量子体积”的指标,这是一个与活跃量子比特数及错误率相关的参数——量子比特数越多,同时错误率越低,则量子体积越大。这与内文定律中的双指数是类似的概念——量子体积随时间指数增长,而量子计算能力随量子体积指数增长。
如果IBM实现量子优势,其部署的多台量子计算云平台将很快可以产生商业价值。或许这正是IBM当前布局的良苦用心吧?
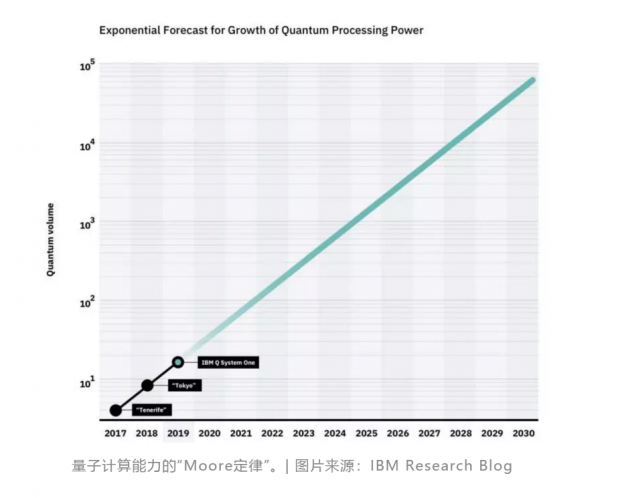
可见,量子优势与量子霸权相比,不是简单的换个概念。量子霸权是一个“里程碑”式的进展,它无疑给科技界、工业界注入了极大的信心,不过它仍是漫漫征程中的一小步,它并不能带来真正的商业价值,而正是这一点,是量子计算能否顺利获得持续的、滚雪球式的资本青睐的关键。
量子优势就是这个关键节点,没有人能预测它在什么时候到来,因为要寻找一个有实际价值的量子算法并演示出来,实在不是一件容易的事。不过我们完全应该保持乐观。比尔·盖茨说过:大多数人会夸大近一两年的变化,而低估未来十年的变化。回望十年前,Transmon量子比特(也就是现在大家普遍采用的比特单元)才刚刚提出来,Google量子计算的扛把子John Martinis还在玩相位量子比特。
最后,量子霸权一出,势必会影响国内各量子计算研究组和公司的研究策略,也会影响国家量子技术发展的布局。这步棋,硬着头皮也要跟。作为局内人自然是倍感压力,不过,给自己,也给同行一句建议:保持清醒,尊重科研规律。
后 记
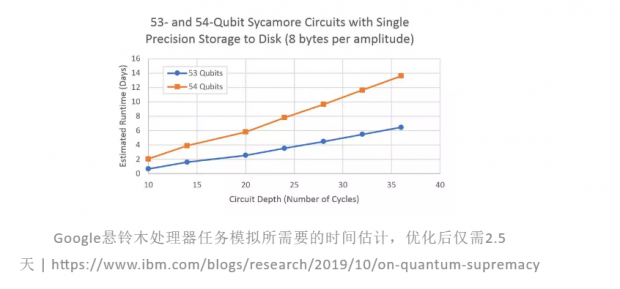
本来已经定稿了,结果又有了“最新进展”:10月21日,IBM在arXiv发表的一篇预印本论文称,Google在用经典计算机模拟的时候优化不够,导致过高的估计了经典计算的开销。按照他们最新的估算,对于同样的任务,一个优化后的模拟计算仅需要2.5天!从这个角度来讲,Google的“量子霸权”就不是真正的霸权了,因为根据其提出者John Preskill的原意,量子霸权必须是量子计算机能做而经典计算机不能做的,2.5天显然不长,毕竟去拉斯维加斯度个周末就算完了。
IBM的一个主要论点是:Google在估计经典计算的开销时,只考虑了超算的并行性和超大的内存,这导致了超过40个量子比特之后薛定谔型模拟无法存储完整的量子态,只能回退到薛定谔-费曼型模拟,以时间换空间。事实上,经典计算机还有很多其他资源可用,比如硬盘!采用内存和硬盘的混合存储方案,就可以直接处理薛定谔型模拟,加上很多其他的优化方法,并在CPU和GPU混合节点上进行计算,53个量子比特,同样的随机量子电路模拟仅需2.5天,即便是54个量子比特,也只要6天。
这篇预印本论文尚未经过同行评议,相信在后续几天里会得到不少专家的评论。笔者大致浏览了一下论文,表示基本看不懂,能得到的就是上述这些信息。此外,这是一篇纯算法分析的论文,尚未真正在超算上跑(这么短的时间,应该代码也没写出来),还不算“实锤”砸碎Google的量子霸权梦。从态度上来讲,这种论文和论点是正向的、严谨的、有必要的,不过一放到Google和IBM互争量子计算头花的竞赛背景中,居然就有了种戏剧性的感觉。此事且待后续各路大神的评论吧,笔者这里先mark一下。
参考资料
http://www.wsdm-
编者的话
现在加密通讯用的密码通常有2000个比特长。那么要用多大的量子计算机才能够破解这个密码呢?本文介绍了量子体积这个概念,用来描写量子计算机的能力。如果我们用Shor的因子分解算法来破解一个N比特长的密码,我们需要一个量子体积大约为 1000 x 3000 N3 的量子计算机*(这里我们假设需要用1000个物理比特来实现一个逻辑量子比特)。所以为了破解长度为2000比特的密码,我们需要一个量子体积为 1016 量级的量子计算机。按照本文中提到的量子计算能力的“Moore定律”,到2055年我们也许会做出这种量子计算机。
在经典加密的经典通讯中,2000个比特并不是密码长度的极限。把密码长度加到100万比特长应该是可以做到的。要破解这样超长的密码,量子计算机的量子体积需要达到 1024 量级。按照本文中提到的量子计算能力的“Moore定律”,到2085年我们也许会做出这种量子计算机。这个量子计算机大约有五十亿个物理比特,做600万亿次计算,就能破解100万比特长的经典密码。
*参考文献:PHYSICAL REVIEW A 86, 032324 (2012); “Surface codes: Towards practical large-scale quantum computation”
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}