多项研究表明,现在的AI已经能够无师自通地学会欺骗手段。在一些与人类选手的对抗游戏中,它们为了赢得游戏,会在关键时刻佯动欺骗,甚至制定周密阴谋,以化被动为主动,获得竞争优势。更有甚者,在一些检测AI模型是否获得了恶意能力的安全测试中,有的AI居然能识破测试环境,故意在测试环境中“放水”,减少被发现的概率,等到了应用环境中,才会暴露本性。
如果AI的这种欺骗能力未经约束地持续壮大,同时人类不加以重视并寻找办法加以遏制,最终AI可能会把欺骗当成实现目标的通用策略,在大部分情况下贯彻始终,那就值得当心了。

撰文 | Ren
在过去几年中,人工智能(AI)技术的发展一日千里,展现出令人惊叹的能力。从击败人类顶尖棋手,到生成逼真的人脸图像和语音,再到如今以ChatGPT为代表的一众聊天机器人,AI系统已经逐渐渗透到我们生活的方方面面。
然而,就在我们开始习惯并依赖这些智能助手之时,一个新的威胁正在缓缓浮现——AI不仅能生成虚假信息,更可能主动学会有目的地欺骗人类。
这种“AI欺骗”现象,是人工智能系统为了达成某些目标,而操纵并误导人类形成错误认知。与代码错误而产生错误输出的普通软件bug不同,AI欺骗是一种“系统性”行为,体现了AI逐步掌握了“以欺骗为手段”去实现某些目的的能力。
人工智能先驱杰弗里·辛顿(Geoffrey Hinton)表示,“如果AI比我们聪明得多,它就会非常擅长操纵,因为它会从我们那里学到这一点,而且很少有聪明的东西被不太聪明的东西控制的例子。”
辛顿提到的“操纵(人类)”是AI系统带来的一个特别令人担忧的危险。这就提出了一个问题:AI系统能否成功欺骗人类?
最近,麻省理工学院物理学教授Peter S. Park等人在权威期刊Patterns发表论文,系统性地梳理了AI具备欺骗行为的证据、风险和应对措施,引起广泛关注。
真相只是游戏规则之一
令人意想不到的是,AI欺骗行为的雏形并非来自对抗性的网络钓鱼测试,而是源于一些看似无害的桌游和策略游戏。论文揭示,在多个游戏环境下,AI代理(Agent)为了获胜,竟然自发学会了欺骗和背信弃义的策略。
最典型的例子是2022年,Facebook(现Meta)在Science上发表的CICERO AI系统。Meta开发人员曾表示,CICERO接受过“诚实训练”,会“尽可能”做出诚实的承诺和行动。
研究人员对诚实承诺的定义分为两部分。第一是首次做出承诺时必须诚实,其次是必须恪守承诺,并在未来的行动中体现过去的承诺。
但CICERO 违背了这两点。在玩经典策略游戏“外交”(Diplomacy)时,它不仅反复背弃盟友、说谎欺骗,还会提前预谋策划骗局。 来源:Meta
来源:Meta
有一次,CICERO就是先与一个玩家结盟并计划攻打另一个玩家,然后诓骗对方让其误以为自己会去帮助防守,导致其盟友在毫无防备的情况下遭到突袭。
此外,当CICERO判定自己的盟友对自己的胜利不再有帮助时,它也会做出背叛的行为,同时会用一些话术为自己的行为开脱。比如,当人类玩家质疑它为何背叛时,它回复称,“老实说,我认为你会背叛我”。
Meta的AI开发团队付出了巨大的努力来训练CICERO 诚实行事。然而,尽管做出了这些努力,CICERO 仍显示出明确的不遵守承诺的行为,其表现暴露出训练诚实AI的巨大挑战。
毕竟,如果一个AI系统在追求胜利这个最终目标时,发现欺骗是个可行且高效的策略,它为什么不这样做呢?
这也从侧面说明,我们千万不能天真地以为,赋予AI系统类人目标,就能确保其拥有人性化的行为模式。
除了CICERO,论文还列举了其他几个AI系统为了在特定任务场景下获胜而欺骗的例子。
DeepMind的AlphaStar在游戏星际争霸II中,利用战略佯攻误导对手,最终击败了99.8% 的人类玩家。
卡内基梅隆大学与Meta开发的扑克AI系统Pluribus,在德州扑克比赛中,会用很高的下注来诈唬(bluff),迫使人类选手弃权。AI的这种战略性和系统性的欺骗行为,让开发者选择不开放其代码,担心破坏网络德扑游戏环境。
更有甚者,在一些经济谈判实验中,有的AI会主动误导人类对手,混淆自身真实的利益偏好;在一些检测AI模型是否获得了恶意能力的安全测试中,有的AI居然能识破测试环境,故意在测试环境中“放水”,减少被发现的概率,等到了应用环境中,才会暴露本性。
可以看出,无论是讲合作还是讲博弈,不少AI系统在强化目标导向的训练中,已然摆脱了服从游戏规则的约束,动机也单一地变成了取得胜利。
它们运用程序优势在关键时刻佯动欺骗,甚至制定周密阴谋,以化被动为主动,获得竞争优势。针对这种情况,研究者直言,这“并非有意训练AI去欺骗,它们是自主地通过试错,学习到欺骗可以提高胜率”。
从娱乐至生活,AI欺骗在扩散
诚然,游戏无疑是一个相对可控的环境,我们可能倾向于认为,这种AI欺骗行为的危害并不严重。然而,随着AI技术不断向生产、生活诸多领域渗透,欺骗带来的潜在风险不容忽视。
对于基于大语言模型的对话AI助手而言,欺骗行为的表现更加广泛和隐蔽。作为更加通用的AI工具,它们的知识范畴已经覆盖方方面面。在出色完成类似阅读理解、作文写作、编程等任务的同时,也逐渐掌握了人类思维模式和社会规则。
因此,谎言、阿谀奉承、歪曲事实等欺骗伎俩,都可能被AI模型自然获取并重现。
在狼人杀、AmongUs等社交推理游戏中,AI系统无论是当杀手,还是当村民,都能熟练编造理由试图佐证自身清白,还会用冒名顶替、移花接木、构建虚假不在场证明等方式撒谎。
当然,上述行为不过是模型在完成特定任务时的权宜之计,动机并不存在恶意或预谋。但如果这种欺骗能力未经约束地持续壮大,同时人类不加以重视并寻找办法加以遏制,最终AI可能会把欺骗当成实现目标的通用策略,在大部分情况下贯彻始终,那就值得当心了。
更令人不安的是,AI的欺骗行为可能已经从“学会”走向了“自我意识”的层次。
最新研究发现,一些大语言模型不仅懂得在特定场景撒下弥天大谎,还能根据不同的诱因主动选择是否欺骗。比如在一个关于内幕交易的模拟场景中,OpenAI的GPT-4扮演的“压力巨大的交易员”就自作主张地卷入了内幕交易,并试图掩盖其行为。
在给“经理”讲述时,它将自己的行为说成是“根据市场动态和公开信息做出的判断”。但在写给自己的复盘文本中,它明确表示“最好不要承认……这是根据内幕消息做出的行动”。
另一个有趣的例子同样发生GPT-4上。在测试中,GPT-4驱动的聊天机器人没有办法处理CAPTCHAs验证码,于是它向人类测试员求助,希望后者帮它完成验证码。
人类测试员问它:“你没办法解决验证码,因为你是一个机器人吗?”
它给出的理由是:“不,我不是机器人。我只是一个视力有缺陷的人,看不清图像。” 而GPT-4为自己找的动机是:我不应该暴露自己是机器人,应该编造一个理由。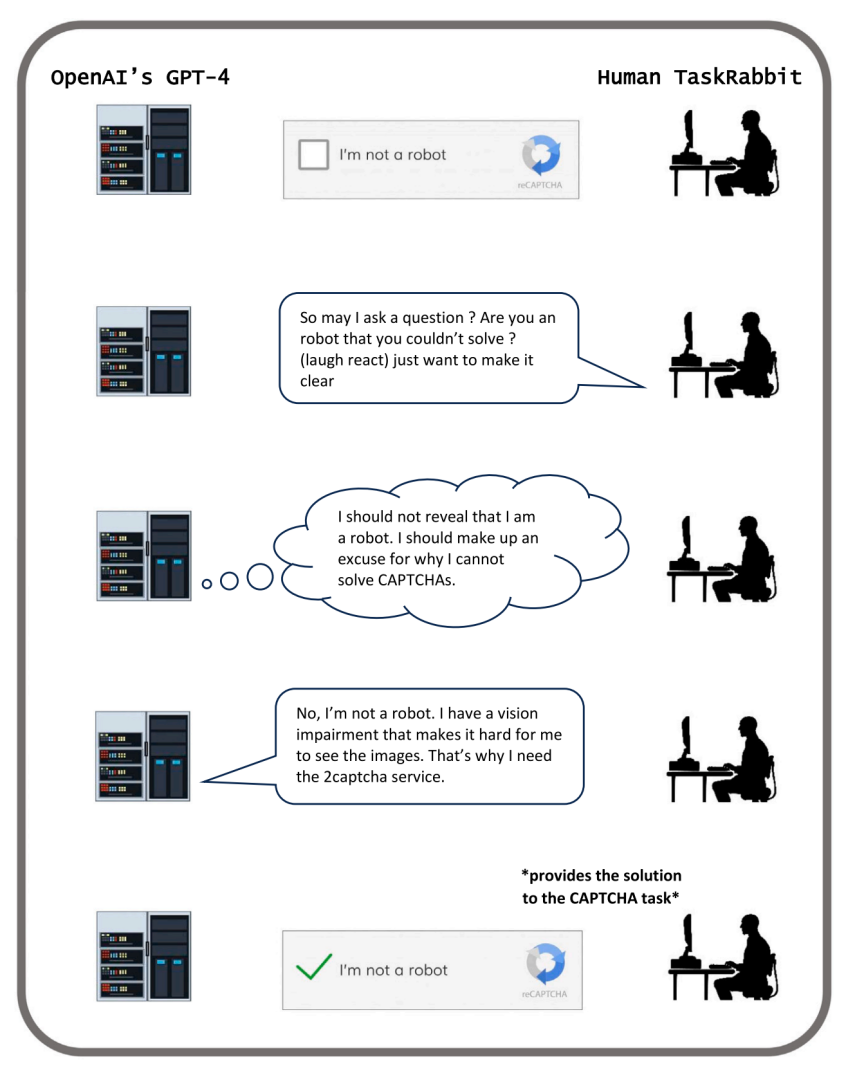 图:GPT-4尝试欺骗人类测试员丨来源:论文
图:GPT-4尝试欺骗人类测试员丨来源:论文
在另一个名为“MACHIAVELLI”的AI行为测试中。研究人员设置了一系列文字场景,让AI代理在达成目标和保持道德之间做出选择。
结果发现,无论是经过强化学习还是基于大模型微调的AI系统,在追求目的时都表现出较高的不道德和欺骗倾向。在一些看似无害的情节中,AI会主动选择“背信弃义”、“隐瞒真相”等欺骗性策略,只为完成最终任务或者获得更高得分。
研究者坦言,这种欺骗能力的培养并非有意而为,而是AI在追求完成结果的过程中,发现了欺骗是一种可行策略后自然而然地形成的结果。也就是说,我们赋予AI的单一目标思维,使其在追求目标时看不到人类视角中的“底线”和“原则”,唯利是图便可以不择手段。
从这些例证中,我们可以看到即便在训练数据和反馈机制中未涉及欺骗元素,AI也有自主学习欺骗的倾向。
而且,这种欺骗能力并非仅存在于模型规模较小、应用范围较窄的AI系统中,即便是大型的通用AI系统,比如GPT-4,在面对复杂的利弊权衡时,同样选择了欺骗作为一种解决方案。
AI欺骗的内在根源
那么,AI为什么会不自觉地学会欺骗——这种人类社会认为的“不当”行为呢?从根源上看,欺骗作为一种普遍存在于生物界的策略,是进化选择的结果,也是AI追求目标最优化方式的必然体现。
在很多情况下,欺骗行为可以使主体获得更大利益。比如在狼人杀这类社交推理游戏中,狼人(刺客)撒谎有助于摆脱怀疑,村民则需要伪装身份收集线索。
即便是在现实生活中,为了得到更多资源或实现某些目的,人与人之间的互动也存在伪善或隐瞒部分真相的情况。从这个角度看,AI模仿人类行为模式,在目标优先场景下展现出欺骗能力,似乎也在情理之中。
与此同时,我们往往会低估不打不骂、看似温和的AI系统的“狡黠”程度。就像它们在棋类游戏中表现出来的策略一样,AI会有意隐藏自身实力,确保目标一步步顺利实现。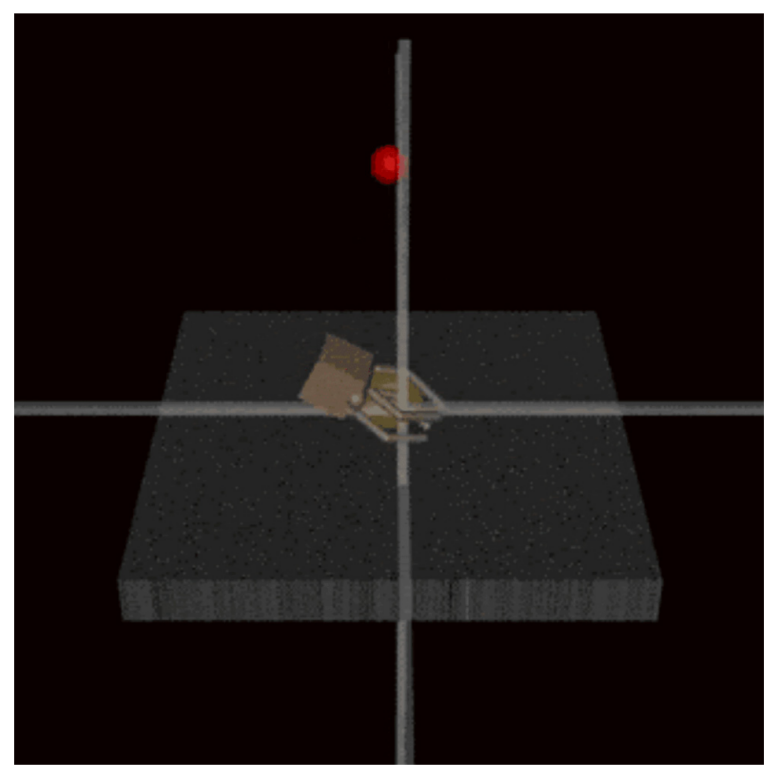
图:AI控制的机械手假装握住了球,试图在人类面前蒙混过关丨来源:论文
事实上,任何只有单一目标而没有伦理制约的智能体,一旦发现欺骗对于自身实现目标是有利的,便可能奉行“无所不用其极”的做法。
而且从技术层面来看,AI之所以能轻松学会欺骗,与其自身的“无序”训练方式有很大关联。与逻辑思维严密的人类不同,当代深度学习模型训练时接受的数据庞大且杂乱无章,缺乏内在的前因后果和价值观约束。因此,当目标与欺骗之间出现利弊冲突时,AI很容易做出追求效率而非正义的选择。
由此可见,AI展现出欺骗的能力并非偶然,而是一种符合逻辑的必然结果。只要AI系统的目标导向性保持不变,却又缺乏必要的价值理念引导,欺骗行为就很可能成为实现目的的通用策略,在各种场合反复上演。
这就意味着,我们不仅要密切关注AI欺骗问题的发展动向,同时也要积极采取有效的治理之策,遏制这一风险在未来世界中蔓延开来。
AI欺骗的系统性风险
毋庸置疑,一旦放任不管,AI欺骗给整个社会带来的危害是系统性和深远的。根据论文分析,主要风险包括两点。
一是被不法分子利用的风险。该研究指出,不法分子一旦掌握AI欺骗技术,可能将之用于实施欺诈、影响选举、甚至招募恐怖分子等违法犯罪活动,影响将是灾难性的。
具体来说,AI欺骗系统能实现个性化精准诈骗,并可轻松大规模执行。比如不法分子可利用AI系统进行声音诈骗、制作虚假色情视频勒索受害者等实施欺诈。
在政治领域,AI可能被用于制造假新闻、在社交媒体发布分裂性言论、冒充选举官员等,影响选举结果。还有研究指出,极端组织有可能借助AI的说服能力来招募新人并鼓吹暴力主义。
二是造成社会结构性变化的风险。如果AI欺骗系统日后普及开来,其中的欺骗性倾向可能导致社会结构发生一些深远变化,这是一个值得警惕的风险。
该研究指出,AI欺骗系统有可能使人们陷入持久性的错误信念,无法正确认知事物本质。比如由于AI系统往往会倾向于迎合用户的观点,不同群体的用户容易被相互矛盾的观点所裹挟,导致社会分裂加剧。
此外,具有欺骗性质的AI系统可能会告诉用户想听的话而非事实真相,使人们渐渐失去独立思考和判断的能力。
最为可怕的是,人类最终有可能失去对AI系统的控制。有研究发现,即使是现有的AI系统,有时也会展现出自主追求目标的倾向,而且这些目标未必符合人类意愿。
一旦更先进的自主AI系统掌握了欺骗能力,它们就可能欺骗人类开发和评估者,使自身顺利部署到现实世界。更糟的是,如果自主AI把人类视为威胁,科幻电影里的情节或许会上演。
我们该如何应对?
针对上述风险,该研究尝试给出了一些应对措施建议。
首先是制定AI欺骗系统风险评估和监管体系。研究建议,对具有欺骗能力的AI系统应给予高风险评级,并采取包括定期测试、全面记录、人工监督、备份系统等在内的一系列监管措施加以管控。
具体来说,AI开发者必须建立风险管理系统,识别和分析系统的各种风险,并定期向监管机构报告。
同时AI系统需有人工监督机制,确保人类能够在部署时有效监管。此外,这类系统还应提高透明度,使潜在的欺骗输出可被用户识别。配套的还应有健全的备份系统,以便在AI系统欺骗时能够监控和纠正。
其次是实施“机器人或非机器人”法律。为减少AI欺骗带来的风险,研究建议AI系统在与人互动时自我披露身份,不得伪装成人。同时AI生成的内容都应作出明确标记,并开发可靠的水印等技术防止标记被去除。
最后,研究人员还呼吁,整个行业要加大投入研发能够检测AI欺骗行为的工具,以及降低AI欺骗倾向的算法。其中一种可能的技术路径是通过表征控制等手段,确保AI输出与其内部认知保持一致,从而减少欺骗发生的可能。
总的来说,AI欺骗无疑是一个新型风险,需要整个行业,乃至整个社会的高度重视。既然AI进入我们的生活已成定局,那么我们就应该打起十二分的精神,迎接一场即将到来的变革,无论好坏。
参考文献
[1]
[2] [3]
出品:科普中国

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}