近日,谷歌量子AI团队公布其量子纠错新进展,他们所构建的表面码纠错大幅降低了错误率,使得逻辑量子比特寿命高于物理量子比特,显著延长了量子信息的存储寿命。这项在量子工程领域具有里程碑意义的工作证明,谷歌团队依然在量子计算机竞赛中占据领先地位。
撰文 | 无邪
四年前,我曾翻译过一篇发表于Science上的评论文章《量子计算的下一个超级大挑战》,这个超级大挑战正是量子纠错。彼时正值谷歌量子AI团队(Google Quantum AI)刚刚完成“量子霸权”的演示,引发全球关注。四年来,全球多个量子计算的顶级团队在向这一超级挑战发起冲击,而谷歌量子AI团队,无疑是其中的先锋队。
最近,谷歌团队在arXiv上贴出了他们的最新成果:低于表面码阈值的量子纠错(Quantum error correction below the surface code threshold)[1]。他们在一片包含105个量子比特的芯片中实现了码距为7(d=7)的表面码纠错,同时在一片72量子比特芯片中实现了码距为5(d=5)的表面码纠错及其实时解码。两种情况下均超过纠错的“盈亏平衡点”,也就是编码后的逻辑量子比特中的信息存储寿命,高于所有参与编码的物理量子比特的寿命。
具体来说,码距为7的逻辑量子比特寿命达到了291微秒,而所有参与编码的量子比特平均寿命为85微秒,最高119微秒。折算下来,量子纠错让量子信息的存储寿命延长了2.4倍。这是一项非常了不起的工程结果,大幅提升了表面码量子纠错的工程可行性,为未来实现具备实用价值的逻辑量子比特注入了强大的信心。我认为这一工作的意义,不亚于当年的“量子霸权”,甚至也不亚于2023年中性原子体系中所取得的量子纠错成果。下面我就尝试讲解一下这一里程碑意义的进展,以及背后的一些技术原理。
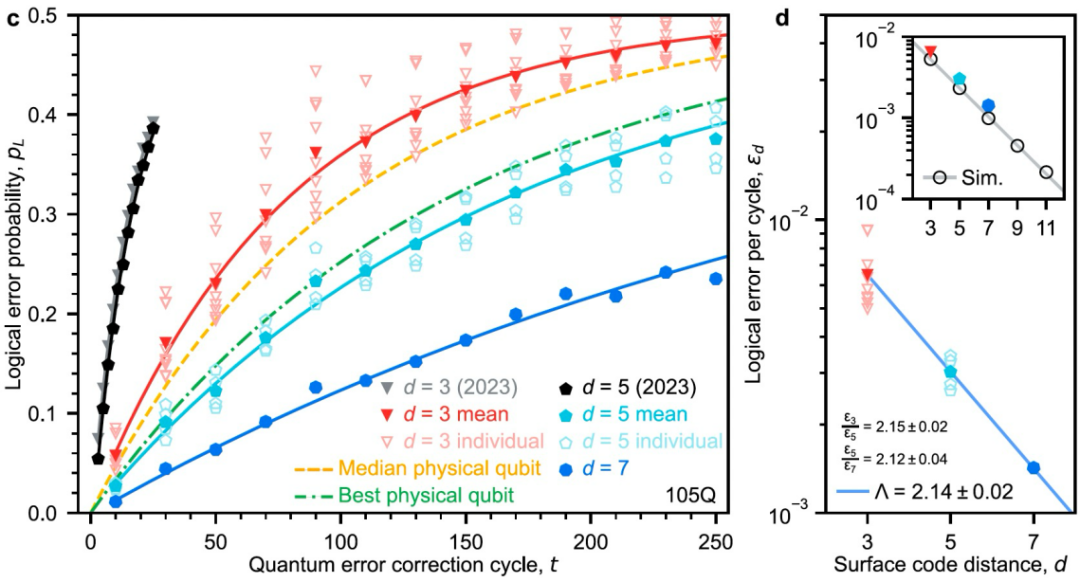
左图为不同码距的表面码纠错下的逻辑错误率,图中同时引用2023年两个d=3纠错码的数据;横轴为纠错周期数,曲线越平缓,表明错误率越低。右图为不同码距错误率拟合的错误抑制系数Λ,在这里为2.14,意味着系统错误率不到表面码纠错错误率阈值的二分之一;随着码距的增加,纠错后错误率将以指数形式快速下降。丨图片来源:参考文献[1]
现实中的量子比特,或者叫物理量子比特,总是会因为各种原因而出错,比如莫名其妙飞过的光子、材料中的某个缺陷,甚至可能是来自遥远宇宙深处的一束宇宙射线。错误会在进行量子计算的过程中累积、传递,导致最终的结果不可用。举例来说,现在的两比特纠缠门错误率在百分之几到千分之几的水平:假设量子门的平均错误率为千分之一,那执行5000个量子门,得到正确答案的概率将低于百分之一;执行10000个门,正确的概率将低至十万分之几;执行20000个门,这个概率将低于亿分之一(这是一个非常粗略的估算,实际的错误累积、传递和关联的情况要复杂得多,正确率将以更快的速度衰减)。这将大幅抵消量子计算所能带来的加速能力,令其威力无法施展。
量子纠错理论的出现,让我们重新燃起了希望。利用冗余的量子比特,以某种方式将它们编码在一起,可以诊断出哪里出错了。如果错误足够“稀疏”,同时又有某些手段及时纠正出错的比特,我们就能够实现量子纠错——得到理想的、不会出错的量子比特,上面说的错误累积也就不会出现,我们总能得到正确的计算结果。
由于这种纠错编码的量子比特的信息并不是存储在某个或某些具体的物理量子比特上,而是以一种纠缠约束的、抽象的形式存在,因此我们将其称为“逻辑量子比特”。早在上世纪末,量子纠错的理论就开始发展:最早的纠错码由Shor和Steane独立提出,接下来Calderbank、Shor和Steane又共同给出了纠错的一般性理论,即著名的CSS码,奠定了量子纠错的基础。随后的一个重要进展是稳定子(stabilizer)概念的提出,为这一领域提供了全新的洞察力,后续很多有用的量子纠错码都是基于这一概念发展的,包括著名的表面码。这也正是谷歌量子AI团队一直坚持采用的技术。
表面码属于更广义的“拓扑码”中的一种,这一编码家族的基本设计理念,是将多个重复的纠错单元“拼接”起来,这种模块化的设计方法使得拓扑码具有良好的可扩展性,符合工程化实现的要求。表面码只需要近邻耦合,对错误率的阈值要求,或者说“门槛”比较低,尽管其编码效率不高,但已成为目前最具工程实现价值的编码方法之一,特别适合于超导量子芯片。
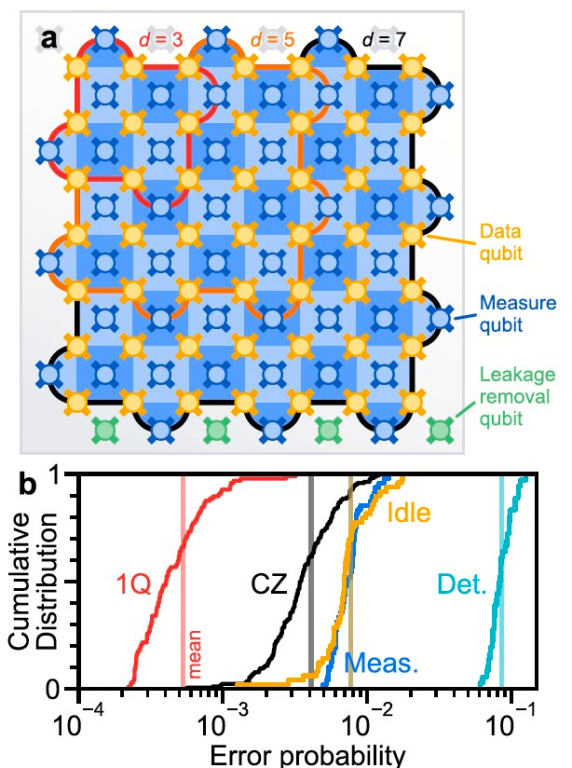
表面编码示意图。图中黄色标记的是数据比特,蓝色标记的是测量比特,绿色标记的是泄漏消除比特。红色、橙色、黑色框线分别标出了码距为3、5、7的编码范围,可以很直观地看出,码距就是数据比特二维阵列的长度,比如码距为3时,数据比特是3x3的阵列。丨图片来源:参考文献[1]
表面码的错误率阈值要求大概在百分之一的水平,此次谷歌量子AI团队所用到的两块芯片,单比特门的错误率达到了万分之五的水平,两比特门达到了千分之四,读取(探测)错误率则达到了千分之八的水平。不过,对于复杂的量子系统,这些单一的指标已经很难描述系统的整体错误情况,正如前面说的,真实的错误比简单的错误累积要复杂得多。因此,谷歌团队又引入了一种更适合描述表面码错误情况的“权重-4探测概率”(就当作是另一种表达系统错误的“指标”)。对于d=7的体系,这个值是8.7%。这表明团队在量子芯片的加工方面有了显著的提升,细节自然不会公开,不过他们提到这归功于“能隙剪裁(Gap-engineering)”技术的应用。无论如何,对于百比特规模的量子计算芯片而言,这已经代表了顶级水平。
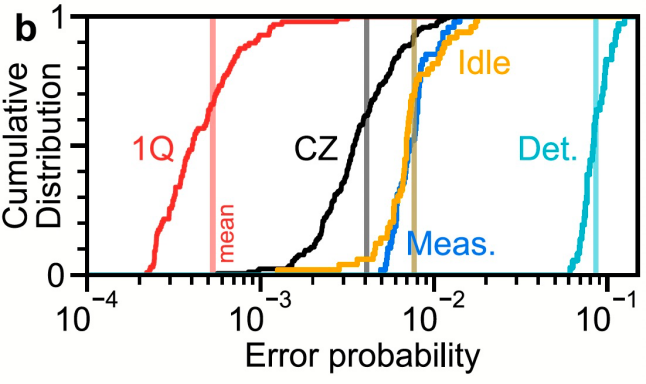
最新的105量子比特芯片性能统计。图中画的是不同类型错误的累计直方图。红色:单比特门错误率;黑色:两比特CZ门错误率;黄色:闲置(即不做任何操作)时的错误率;蓝色:读取(测量)错误率;浅蓝:权重-4探测概率。
还有几个亮点值得提一下,一个是实时解码技术。表面码量子纠错需要不断地制备稳定子,对辅助量子比特进行测量并重置,然后再重复这一过程。在这个过程中,我们需要对测量结果进行解码,以保持对错误症候的追踪,并在需要对逻辑量子比特进行操作时及时纠正错误。显然,实时解码对于实用的容错量子计算是必要的,不过对解码器的性能也提出了极为苛刻的要求。特别是超导量子体系,因为门执行的速度太快了,上述一个周期将在1微秒左右完成,这意味着需要在同样的时间内完成解码。正是这个原因,过往的量子纠错实验,一般是将测量数据先存起来,之后用一个离线解码器处理。这次谷歌团队首次在d=5的纠错流程中实现了长时间的连续实时解码,在一百万个周期下,解码器的平均延时为63微秒,没有表现出延时随周期数逐渐增长的情况,表明解码器能够跟上纠错码的执行节奏——大概是每周期1.1微秒。实时解码器会带来一定的性能下降,不过仍能保持一个2倍以上的错误抑制系数。团队并没有在d=7的纠错码中应用实时解码技术,表明其中的挑战性是非常大的。未来如何在更大码距的纠错码中实现实时解码,将一直是一个极富挑战的技术难题。
另一个亮点是团队为了试探系统的错误率背景极限,测试了码距为29的“重复码”——它可以看作表面码的一维情况,它不能同时侦测所有的Pauli错误(指错误可以表示为Pauli矩阵的线性组合;举例来说,量子态绕X或Z轴翻转了180度),只能侦测比特翻转或相位翻转中的一种。测试结果表明,在码距达到大约25之后,逻辑错误率就饱和了,大概为百亿分之一(10-10)的水平。团队发现这一背景错误率来源于大约每小时发生一次的不明来源的关联错误。而在之前的芯片上,这个错误率背景是百万分之一,团队认为这是由于大概几十秒一次的高能事件,也就是宇宙射线轰击芯片所导致的。因此,这有可能成为未来量子纠错技术的一个新课题。
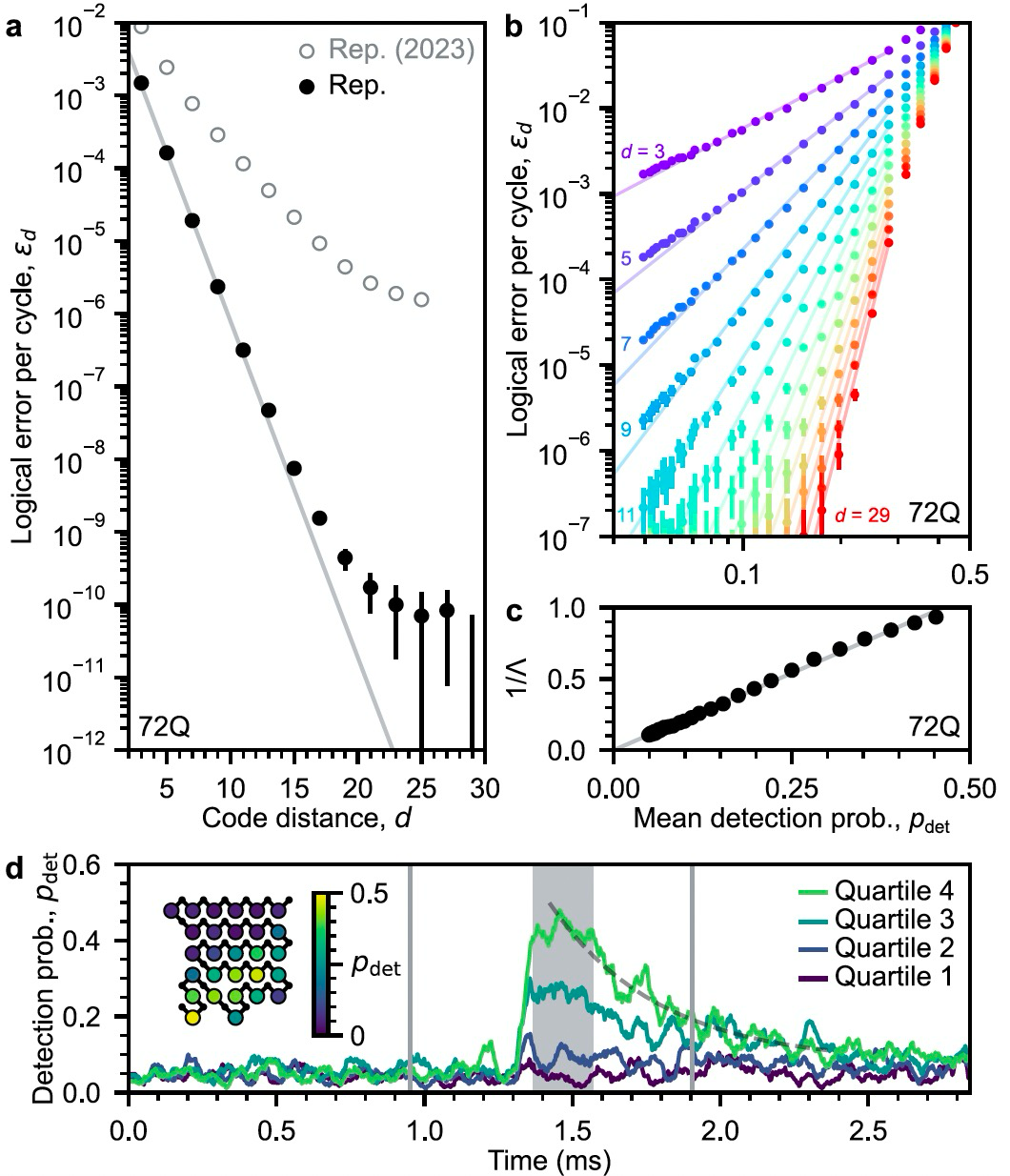
不同码距重复码纠错后的逻辑错误率。随着码距的增加,错误率会逐渐偏离理论预测值;当码距达到25时,错误率达到一个饱和的背景值,约百万分之一。这可能与一些发生率很低(大约1小时一次)的不明原因关联错误有关。丨图片来源:参考文献[1]
总而言之,这是一个非常了不起的工作,谷歌再次证明了他们顶级的量子计算工程技术能力。作为同行,我既感到兴奋,也感到忧虑。感到兴奋,是因为这是朝容错通用量子计算迈出的重要一步,是大量量子工程技术的系统性进步,让全世界看到了更多的希望。感到忧虑,则是站在国家角度,这有可能意味着在量子计算领域中美之间的差距在无形中拉大。要知道,谷歌仅是美国量子计算的顶级团队之一,IBM、麻省理工学院等同样具备类似的能力。在现在的阶段,这种能力往往表现在系统工程方面,而非科学问题。我们以谷歌、IBM等团队作为技术标杆,却少有思考他们是如何组织,如何权衡与协调工程技术与科学问题之间的关系,如何让优秀的工程师与科学家协同攻关,等等。从这篇论文的作者结构来看,这是一项大型的工程合作典范,除了谷歌量子AI团队,还有DeepMind团队、马萨诸塞大学、加州大学圣巴巴拉分校、康涅狄格大学、奥本大学、苏黎世联邦理工学院、耶鲁大学、麻省理工学院等共13家单位/团队,参与人数超过200人。这样的大规模合作,在中国要如何发生呢?如果我们不转变思维,着力打造工程导向、企业化组织的新型团队;如果我们迟迟没有具有大胸怀、拥有顶级号召力的科学家站出来;如果我们的科技激励机制仍以数文章,拼Nature、Science为核心导向;如果……或许还有很多如果;再叠加上欧美持续对我们的人才和技术限制,在量子计算工程方面,我们可能很难破局。
我们需要勇气,我们需要定力,我们更需要团结。我自不堪,唯愿有真国士出,领一批优秀的工程师,和各地卓越的科学家,向实用量子计算踔厉前行,走出坚实的中国步伐。
后记:就在稿子编辑的这几天(9月10日),微软蓝天量子(Microsoft Azure Quantum)团队首次在催化反应手性分子模拟中,演示了“端到端”的高性能计算(HPC)、量子计算和人工智能组合[2]。在量子计算部分,他们采用了C4码纠错保护的逻辑量子比特来进行基态制备,而不是物理量子比特。可见量子纠错将快速成为量子计算工程技术的主战场,而我国的量子计算工程能力急需提升以应对这些竞争。
参考文献
[1]
[2]

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}