探究宇宙中的秩序和混沌一直是科学研究的核心命题。陶哲轩教授的这篇洞察性文章引领我们进入普适的世界——一个展现了如何从错综复杂的微观动态系统中抽象出简明的宏观规律的奇妙领域。从统计学的经典规律到物理学中的相变现象,从自然数序列的神秘规律到量子力学的精确预测,普适性作为一种被广泛记录和验证的模式在各种不同尺度和领域中展现了其惊人的一致性。然而,尽管这些规律已被实证学科反复确认,但对于普适性的严格数学基础仍存在着诸多未知之谜。本文通过综合不同领域中的具体案例和研究成果,展示了当前科学界对这些宏观规律涌现机理的理解,并指出了这一研究领域所面临的挑战与前沿问题。
撰文 | 陶哲轩
译者 | 米凯
审校 | 王至宏、苑明理

论文题目:
E pluribus unum: From Complexity, Universality
论文链接:
~aldous/157/Papers/tao_universality.pdf
目录
0. 复杂系统与简单法则
1. 大数定律
2. 中心极限定理
3. 相变与重整化群
4. 离散谱、随机矩阵模型、黎曼猜想
5. 普适性的失效与复杂性的出现
摘要:在这篇简短的报告中,我讨论了关于复杂系统中普适性这一迷人现象的一些例子,普适性现象指的是从多种不同的微观动力学行为中涌现出来的、普遍的宏观自然规律。这些现象在实证上被广泛观察到,然而在一般情形下,普适性的严谨数学基础仍未能令人满意。
自然是一朵变幻莫测的云,永远如一,又从不相同。
—— Ralph Waldo Emerson,《历史》(1841年)
0
复杂系统与简单法则
现代数学是一种强大的工具,它能够模拟无数的现实世界情景,不论是自然界中的——例如天体运动,或材料的物理及化学属性——还是人为创造的情景:比如股票市场或选民的投票倾向[1]。原则上,即使是包含诸多相互作用组件的极端复杂系统,也能通过数学模型进行研究。
然而,在实践中,我们只能精确求解非常简单的系统(那些仅包含两到三个相互作用主体的系统)。例如,在本科的物理课程中,我们能给出氢原子光谱线的数学推导,这是因为氢原子中只有一个电子绕核运动;但是,即便使用最先进的计算机,我们也无法完成对钠原子光谱线的数学推导,钠原子有十一个电子,这些电子之间以及它们与原子核之间都存在相互作用。
三体问题是指根据牛顿的万有引力定律预测三个物体的运动,据说这是唯一令牛顿感到头疼的问题。不同于有着简单数学解答的两体问题,人们普遍认为三体问题没有简洁的数学公式可以解决,它只能通过数值算法进行近似求解。在一个包含许多相互作用组件的系统上无法执行切实可行的计算,这一现象被称为“维数诅咒”。
尽管存在这个诅咒,但是当组件数量足够大时,通常会出现一个令人惊奇的现象:复杂系统的聚合属性可以不可思议地再次变得可预测,并由简单的自然法则支配。
译注:
聚合属性(aggregate properties)指的是复杂系统的整体性质或总体特征。当一个系统由许多相互作用的组件组成时,这些组件的集合会表现出一些共同的特征,这些特征可以被称为“aggregate properties”。这些特征可能是系统的平均值、总和、分布或其他统计量,它们描述了系统作为一个整体的行为或性质。这些特征不仅取决于系统中各个组件的性质,还受到它们之间相互作用的影响。通过研究和理解这些“aggregate properties”,我们可以更好地了解和预测复杂系统的行为。
更令人惊讶的是,整个系统的宏观规律常常在很大程度上与控制系统内部单个组件的微观规律无关。换句话说,人们可以用完全不同类型的对象替换微观组件,并在宏观层面上获得相同的控制规律。这意味着,无论系统的微观组成如何,只要系统的组件数量足够多,宏观规律就会出现,并且这些规律可以独立于微观组件的特性而存在。我们就说宏观规律是普适的。
普适性现象在许多不同的情境中都已经实证地和在数学上被观察到,其中几个例子我将在下文中进行讨论。在一些案例中,我们已经对这种现象有了很好的理解,但在许多情况下,它的潜在来源仍然颇具神秘色彩,并且仍然是数学研究中的一个活跃领域。
1
大数定律
2008年11月4日的美国总统选举是一场极其复杂的事件。来自50个州的超过一亿选民投下了他们的选票,每个选民的决定都受到竞选言论、媒体报道、谣言、选民对候选人的个人印象以及朋友和同事的政治讨论等无数方式的影响。有数百万的“摇摆选民”并不坚定地支持两位主要候选人中的任何一位,他们的最终决定可能无法预料,甚至在某些情况下可能是随机的。在州一级,同样存在着不确定性:虽然许多州被认为对某一位候选人来说是安全的,但至少有十几个州被认为是"摇摆州",可能会倒向任何一方。
在这种情况下,准确预测选举结果似乎是不可能的。当然,存在着成百上千次的选举民调,但每次民调只针对数百或数千名潜在选民,仅仅占选民群体中的一小部分。而且民意调查经常波动很大,彼此相左;并非所有的民意调查都同样可靠或无偏见,没有两个民意调查机构使用完全相同的方法。
尽管如此,在选举之夜结束之前,民意调查已经相当准确地预测了总统选举(以及当晚举行的大多数其他选举)的结果。也许最引人注目的是统计学家内特·西尔弗(Nate Silver)的预测,他使用了所有现有民意调查的加权分析来正确预测了49个州的总统选举结果,以及所有35场美国参议院选举。(唯一的例外是印第安纳州的总统选举,西尔弗将其判定为麦凯恩获胜,但最终奥巴马以仅0.9%的微弱优势获胜。)
民调的准确性可以通过一个称为“大数定律”的数学原理来解释。这一法则告诉我们,只要随机样本的规模足够大,民调的潜在结果就会趋近于实际上愿意投票给特定候选人的选民比例,直到达到一定的精度水平,也就是我们所说的误差范围(margin of error)。例如,在对一千名选民进行的随机民调中,误差范围大约为3%。
译注:
大数定律(Law of large numbers):在数学与统计学中,大数定律又称为大数法则、大数律,是描述相当多次数重复实验后的结果的定律。根据这个定律,随着样本数量的增加,其算术平均值越来越有高的几率接近期望值。
大数定律非常重要,因为它“说明”了一些随机事件均值的长期稳定性。人们发现,在重复试验中,随着试验次数的增加,事件发生的频率趋向于一个稳定值;人们同时也发现,在对物理量的测量实践中,测定值的算术平均也具备稳定性。比如,我们向上抛掷一枚硬币,硬币落下后哪一面朝上是偶然的,但当我们抛硬币的次数足够多后,达到上万次甚至几十万、几百万次之后,我们会发现硬币每一面向上的次数约占总次数的二分之一,亦即偶然中包含着必然。参见维基百科:
大数定律的一个显著特点是它的普适性。选举涉及10万选民还是1亿选民并不重要:民意调查的误差范围仍然是3%。同样,这个州55%对45%支持麦凯恩,还是60%对40%支持奥巴马,这个州是一个由富裕的白人城市选民组成的同质化集团,还是一个由各种收入、种族和背景的选民混合而成的州,这无关紧要:调查的误差范围仍然是3%。唯一显著影响误差范围的因素是民调的规模;民调规模越大,误差范围越小。1亿选民在决定总统候选人时所面临的巨大复杂性最终可以简化为只有几个数字。
大数定律是数学和自然界中最简单、最容易理解的普适性规律之一,但它绝不是唯一的一个。几十年来,人们发现了许多类似的普适性规律,它们适用于控制广泛类型的复杂系统的行为,无论系统的组成部分是什么,它们如何相互作用。
对于大数定律,这一普适性现象的数学基础是很好理解的,并且在概率和统计学的本科课程中经常教授。然而,对于许多其他普适性规律,我们的数学理解还不够完善。探寻复杂系统中频繁出现普适性规律的原因,是数学研究中一个非常活跃的方向。在大多数情况下,我们离这个问题的满意答案还很远,但正如我下面所讨论的,我们已经取得了一些令人鼓舞的进展。
2
中心极限定理
在大数定律之后,也许另一个最基本的普适性规律的例子是中心极限定理(Central Limit Theorem)。粗略地说,这个定理断言,如果一个统计量是由许多独立且随机波动的组成部分组合而成,且没有一个组成部分对整体有决定性影响,那么这个统计量将近似地按照一种称为正态分布(或高斯分布)的规律分布,或者更通俗地称为钟形曲线。这个规律是普遍的,因为无论个别成分如何波动,或者成分有多少个,它都成立(尽管成分数量越多,规律的准确度越高)。
译注:
中心极限定理(Central Limit Theorem,CLT)是概率论中的一组定理。在概率论中,中心极限定理表明,在许多情况下,对于独立且同分布的随机变量,即使原始变量本身不是正态分布,标准化样本均值的抽样分布也趋向于标准正态分布。这组定理是数理统计学和误差分析的理论基础,它指出了大量随机变量之和近似服从正态分布的条件。参见维基百科:
中心极限定理在范围极广的统计数据中得到体现,从事故发生率到不同物种个体的身高、体重或其他关键统计数据的变化,再到由偶然事件导致的财务盈亏,以及物理系统中各组成粒子的速度,都能找到它的踪迹。这些分布的大小、宽度、位置乃至测量单位随着不同的统计而有所不同,但钟形曲线的形状却能在所有实例中被识别出来。这种趋同并非因为车祸、人类身高、交易利润或星体速度等多样化现象之间存在的“低级”或“微观”层面的联系,而是因为在所有这些情况下,其“高级”或“宏观”结构相同:即由许多独立因素的小影响组合成的复合统计量。一个大型复杂系统的宏观行为几乎完全与其微观构造无关,这正是普适性的要义。
中心极限定理的普适性在许多行业中非常有用,它允许这些行业管理本来难以处理的复杂和混乱的系统。有了这个定理,保险公司可以管理他们的汽车保险政策的风险,而不必知道车祸发生的所有复杂细节;天文学家可以测量遥远星系的大小和位置,而不必解决天体力学的复杂方程;电气工程师可以预测噪声和干扰对电子通信的影响,而不必知道这种噪声是如何产生的;等等。然而,中心极限定理并不是完全普遍的;一些重要情况下定理不适用,其给出与钟形曲线完全不同的分布统计数据。(我稍后会回到这一点。)
中心极限定理存在着一些扩展,它们是针对某些略有不同的统计数据类型的普适性规律。本福德定律(Benford's Law)就是一个例子,它是关于大量级统计数据的前几位数字的一个普适性规律,如一个国家的人口数量或账户的金额大小;这个法则给出了一些反直觉的预测,比如,在自然界中出现的任何给定统计数据都更可能以数字1开头,而不是数字9开头——实际上以1开头的概率是以9开头的六倍多。除此之外,本福德定律(可以通过结合中心极限定理和对数的数学理论来解释)还被用于检测会计欺诈,因为与自然产生的数字相比,被人为编造的数字往往不符合本福德定律。
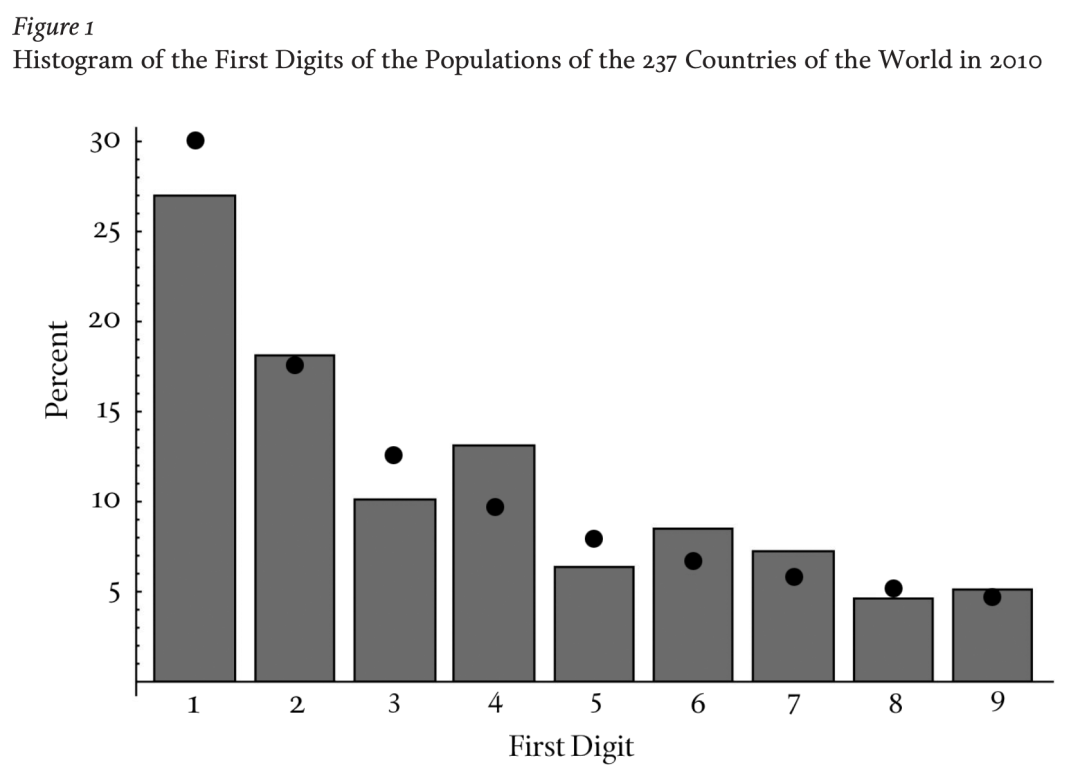
图1. 2010年世界237个国家人口的首位数字的直方图。黑色的点表示 Benford 定律的预测。|图源:维基百科,:Benfords_law_illustrated_by_world%27s_countries_population.png
译注(来源于维基百科):
本图表使用世界各国的人口为例,说明本福德定律(Benford's law)。图表显示了各国人口第1位数字所占的百分比(灰色柱状图)。例如,237个国家中有64个(占27%)的人口以1为首位数字。黑色点表示本福德定律的预测结果。数据来自CIA世界手册 ,访问时间为2010年8月7日。
类似地,Zipf 定律是描述特定类别中最大统计量的普适性规律,例如世界上人口最多的国家或英文中使用频率最高的单词。它指出,统计数据的大小通常与其排名成反比;因此,例如,第十大的数据大约是第五大数据的一半大小。这个法则对于最顶端的两三个数据可能不太精确,但在之后的数据中准确性提高。与数学上较容易理解的中心极限定理和本福德定律不同,Zipf 定律是基于经验的。它是通过实践观察而确定的,但数学家们尚未给出一个完全满意和有说服力的解释,来说明这个定律怎样产生以及为什么具有普适性。
译注:
Zipf定律是一种经验规律,当一个测量值列表按降序排序时,它通常大致成立。它指出,第n个条目的值与n成反比。Zipf定律最著名的实例适用于自然语言文本或语料库中单词的频率表。通常情况下,最常见的词出现的频率大约是次常见词的两倍,是第三常见词的三倍,依此类推。
来源于维基百科:
3
相变与重整化群
目前为止,我讨论了个体统计量的普适性规律:当多个小的独立因素复合时,就会产生这些复杂的数值量。然而,除了数值统计之外,更加复杂的对象也遵循普适性规律。以物理和化学中相变引起的复杂形状和结构为例。正如我们在高中科学课上所学的,物质存在不同状态,包括三种经典状态——固态、液态和气态,还有一些奇异状态,比如等离子体或超流体。例如铁这样的铁磁性材料,也存在磁化和非磁化的状态;其他材料可能在某些温度下是导体,在另一些温度下则是绝缘体。材料的状态取决于许多因素,尤其是温度,有时还包括压力。(对某些材料而言,杂质水平也是重要因素。)在固定压力下,大部分材料倾向于在一个温度区间内呈现某种状态,在另一个区间内呈现另一种状态。但当材料的温度达到或非常接近这两个区间的分界线时,便会发生有趣的相变现象。此时的材料并未完全处于其中一种状态,往往会分裂成为美丽的分形形状,称为簇(clusters),每个簇代表两种状态中的一种。
译注:
分形(英语:fractal,有“零碎”、“破裂”之意),又称碎形、残形,通常被定义为“一个粗糙或零碎的几何形状,可以分成数个部分,且每一部分都(至少近似地)是整体缩小后的形状”,即具有自相似的性质。分形在数学中是一种抽象的物体,用于描述自然界中存在的事物。人工分形通常在放大后能展现出相似的形状。分形也被称为扩展对称或展开对称。如果在每次放大后,形状的重复是完全相同的,这被称为自相似。
参考链接:
现实世界存在无数种材料,每一种都有一组关键特性参数(例如,在给定压力下的沸点)。物理学家和化学家们采用了许许多多数学模型来模拟这些材料及其相变。在这些模型中,通常会假设单个原子或分子通过随机数量的键与一些周围邻居连接,且这些连接按某种概率规律来分配。在微观尺度上,这些模型之间可能差异显著。例如,下面的插图展示了两种典型模型的小尺度结构:
图2所示为六角形晶格上的点渗流模型(site percolation model),每个六边形(或位点)为原子或分子的抽象化,它们被随机赋予两种状态之一,相同状态的连接区域组成簇;

图2 临界阈值下的六边形晶格点渗流模型。图源:Michael Kozdron,~kozdron/Simulations/Percolation/percolation.htm
图3所示为正方形晶格上的键渗流模型,其中晶格的边缘为分子键的抽象化,每个键有一定几率被激活,由激活键连接成的区域形成簇。

图3 方格渗流模型在临界阈值下的键渗流模型。注意这里既有非常小的簇,也有极大的簇。图源:维基百科,
:Bondpercolationp_51.png
当我们从宏观角度审视簇的大尺度结构时,特别是在接近临界参数值(例如,温度)的情况下,微观结构上的差异开始变得模糊不清,一些普适性规律也随之涌现。尽管簇的大小和形状是随机出现的,但它们几乎总会呈现出分形结构;这意味着如果你放大观察簇的任何一个部分,其显示的图像都会或多或少地类似于整个簇。基本统计量,比如簇的数量、簇的平均大小或簇连接两个特定空间区域的频率等,都遵循一些特有的普适性规律,被称作幂律(这些与Zipf定律类似,但并非完全一样)。这些规律几乎存在于每一个用来解释(连续)相变现象的数学模型中,并且在自然界中被反复观察到。就像其他普适性规律一样,模型或材料的确切微观结构可能影响一些基础参数,比如相变温度,但无论在哪个模型或材料中,这些规律的基础结构都是一致的。
与中心极限定理等更经典的普适性定律不同,我们对相变的普适性规律的理解还不完全。物理学家提出了一些令人信服的启发性论证,解释或支持了许多这些规律(这些论点基于一种强大但不完全严谨的工具,称为重整化群方法 (renormalization group)),但在一般情形下还没有得到这些规律的完全严格证明。这是一个非常活跃的研究领域;例如,在2010年8月,菲尔兹奖(数学界最负盛名的奖项之一)授予斯坦尼斯拉夫·斯米尔诺夫(Stanislav Smirrnov),以表彰他在严格建立一些关键模型(如三角晶格上的渗流模型)的普适性规律的有效性方面取得的突破。
译注1:
重整化群方法:在理论物理中,重整化群(renormalization group,简称RG)是一个在不同长度标度下考察物理系统变化的数学工具。标度上的变化称为“标度变换”。重整化群与“标度不变性”和“共形不变性”的关系较为紧密。共形不变性包含了标度变换,它们都与自相似有关。在重整化理论中,系统在某一个标度上自相似于一个更小的标度,但描述它们组成的参量值不相同。系统的组成可以是原子、基本粒子、自旋等。系统的变量是以系统组成之间的相互作用来描述。
资料来源:
译注2:
三角晶格上的渗流模型(percolation models on a triangular lattice):三角格点上的点渗流是少数几个精确解的统计系统之一。从随机放置的临界渗流集群的黑色或白色位点开始,我们随机重新分配每个渗流集群的颜色,并通过合并相同颜色的集群获得粗粒化构型。研究表明,在热力学极限下,这个过程可以无限迭代,从而得到一个迭代渗流模型。此外,根据自匹配论证,猜想渗流集群在任何有限的代数中仍然是分形的,甚至可以通过广义过程取任意实数。进行了大量的模拟,并从代数相关的分形维度中揭示了一个连续的以前未知的普适性。最后,通过类似的过程,定义了临界键渗流集群的迭代渗流。参见:
Iterative Percolation on Triangular Lattice - .
4
离散谱、随机矩阵模型、黎曼猜想
在我们对普适性规律的探索即将结束之际,我想考虑一个更贴近我研究领域的现象示例。在此,我们关注的不是单一的数值统计(如在中心极限定理中的情况),也不是形状(如在相变中的情况),而是一个离散谱:这是沿直线分布的一系列点(或数值、频率、能级)。
最常见的离散谱例子或许是当地广播电台发射的无线电频率;它们构成了电磁光谱中无线电范围内的一个频率序列,人们可以通过旋转收音机的调频钮来选择接收。这些频率不是等距排列的,但为了减少相互干扰,通常会努力确保各个广播电台的频率之间有一定的分隔。
另一个熟知的离散谱例子是原子元素的光谱线,根据量子力学定律 (laws of quantum mechanics),它来自于原子壳层中的电子能够吸收和发射的频率。当这些频率位于电磁谱的可见光部分时,它们赋予各个元素独特的颜色,从氩气的蓝光(令人困惑的是,氩气通常用于霓虹灯,因为纯氖发出橙红色光)到钠的黄光。对于诸如氢这样的简单元素,量子力学方程可以相对容易地解决,光谱线遵循一种规律的模式;但对于较重的元素,光谱线变得相当复杂,仅仅依靠基础原理并不容易推导出来。
译注:
光谱线是当原子中的电子吸收或发射能量时形成的,导致它们在不同能级或轨道之间移动。原子的能级是量子化的,意味着只有特定的离散能级是允许的。这导致在与允许能级之间的能量差对应的特定波长处形成光谱线。例如,在氢的情况下,当一束白光(由所有可见波长的光子组成)通过氢原子的气体时,只有具有特定能量的光子可以被氢原子吸收。这些光子对应于氢原子的允许能级之间的能量差。因此,氢原子只在特定波长处吸收光,并在光谱中产生相应的暗线。类似地,当氢原子中的电子从较高能级向较低能级移动时,它们会发射能量与两个能级之间的能量差相对应的光子。这导致在特定波长处形成明亮的发射线。光谱线中观察到的规律模式是由于原子能级的量子化。能级遵循一种规律模式,因此由这些能级之间的跃迁形成的光谱线也遵循一种规律模式。这种规律模式可以用于识别元素并确定它们的性质。例如,天文学家使用光谱线来确定恒星和其他天体的组成。
参考来源:
(1)Formation of Spectral Lines
(2)Absorption spectrum (emission spectrum lines) :structure-of-atom/x98cdf762ed888601:bohr-s-model-of-hydrogen-atom/a/absorptionemission-lines
一个类似但不常见的谱的例子来自原子核(如铀-238核)对中子的散射。结合量子力学定律以及原子核的电磁力和核力作用,预测在某些能量下中子可以几乎无阻碍地穿透原子核,在其他能量下则被原子核反弹,这些特殊的能量点称为散射共振点。因为这些大型原子核的内部结构复杂到无法从理论上或通过数值计算来预测这些共振点,我们只能依靠实验数据来进行研究。
这些共振具有有趣的分布特征;它们并不彼此独立,而是似乎遵循一种精确的排斥规律,使得两个相邻的共振不太可能彼此靠近,有点类似于无线电台频率倾向于避免彼此靠近,只是前者现象源自自然定律,而非政府对频谱的调控。在20世纪50年代,著名物理学家和诺贝尔奖得主尤金·维格纳(Eugene Wigner)研究了这些共振统计数据,并提出了一个非凡的数学模型来解释它们,就是我们现在所称的随机矩阵模型(random matrix model)。这些模型精确的数学细节太过技术性,在此不便描述。但总的来说,可以将这样的模型看作是一个大量质量的集合,所有质量都通过各种随机选择的、不同强度的弹簧连接在一起。这样一个机械系统将在一定的频率下振荡(或共振);维格纳假设认为,大型原子核的共振应该类似于随机矩阵模型的共振。特别地,它们应呈现相同的排斥效应。因为可以严格证明随机矩阵模型的频率排斥,所以可以对核共振实验观察到的相同现象提供启发式的解释。
译注:
随机矩阵理论(RMT)利用统计力学的原理来模拟多个数学领域中复杂系统的交互作用。它最初被用于模拟重原子的核,后来被用于估计大量统计样本中的协方差,并预测著名的黎曼ζ函数零点的分布。更现代的应用包括理论神经科学和最优控制。
随机矩阵,顾名思义,随机矩阵是任意具有随机元素的矩阵,其元素为非负实数,且行和或列和为1。如果行和为1,则称为行随机矩阵;如果列和为1,则称为列随机矩阵;如果行和和列和都为1,则称为双随机矩阵。创建随机矩阵的一个简单方法是创建一个N × N矩阵,其中元素来自N(0,1)分布。然而,这个矩阵会有复数和重复的特征值。一般而言,实特征值才会有意义,特别是如果恰好有N个特征值。因此,如果研究限制在对称矩阵的情况,将产生N个实特征值。这些矩阵称为高斯正交(GOE)中的样本,也称为GOE矩阵。
当然,原子核实际上并不像一个大型的质量和弹簧系统(除了其它因素外,它受量子力学而非经典力学的定律支配)。相反,正如我们后来发现的,维格纳的假设是一种普适性规律的体现,它支配着许多类型的光谱线,包括那些与原子核或随机矩阵模型看似没有太多共同点的光谱线。例如,在墨西哥库埃尔纳瓦卡的一个公交车站,人们发现公交车之间的等待时间存在相同的间距分布(尽管对于为什么这种分布会在这种情况下会出现,目前尚无令人信服的解释)。
也许对这些普适性规律最出人意料的证明来自于数论这一完全不相关的领域,尤其是质数分布——如2、3、5、7、11等,它们是大于1且不能被分解成更小因子的自然数。质数在整数中的分布是无规则的;然而,如果进行这种分布的谱分析,可以发现分布中存在某些长期振荡(有时称作质数的乐曲),其频率由一串复数序列描述,即所谓的黎曼 ζ 函数的非平凡零点,它在1859年首次由伯恩哈德·黎曼(Bernhard Riemann)研究。(对这里的讨论,黎曼 ζ 函数究竟是什么并没有那么重要。)
译注:
黎曼ζ函数是一个数学函数,由德国数学家伯恩哈德·黎曼在1859年首次研究。它是一个复变函数,定义在复平面上的所有复数(除了1以外的正整数)。黎曼ζ函数在数论中具有重要的作用,它与质数的分布和素数定理之间有密切的关联。黎曼猜想是关于黎曼ζ函数零点分布的一个重要假设,它认为这些零点都位于复平面上的一条直线上。尽管黎曼猜想尚未被证明,但它对于理解质数的分布和数论的许多重要结果具有重要影响。
原则上,这些数字告诉我们关于质数的一切我们希望知道的信息。数论中最著名和重要的问题之一是黎曼假设,它断言这些数字都位于复平面上的一条直线上。该猜想在数论领域有着广泛的影响,特别是给出了许多关于质数的重要推论。然而,即使是强大的黎曼假设也没有解决这个主题的一切问题,部分原因是它并没有直接说明零点在这条直线上的分布情况。但是,有极强的数值证据表明,这些零点遵循与中子散射和其他系统中观察到的同样的精确定律;特别地,零点的分布方式使得相邻的两个零点之间似乎彼此“排斥”,这一现象已经被观察到,与随机矩阵理论预测惊人地相符。这个定律的正式描述称为高斯酉集(Gaussian Unitary Ensemble,GUE)假设。(GUE是随机矩阵模型的一个基本例子。)像黎曼假设一样,它目前尚未被证明,但它对质数分布有强大的影响。
译注:
在随机矩阵理论中,已知黎曼ζ函数的零点具有一种被称为蒙哥马利的对相关猜想的特定性质。这个猜想表明,这些零点在相邻级别之间倾向于相互排斥。也就是说,这些零点的分布方式使得相邻的两个零点之间很不可能太靠近。这一现象已经被观察到与随机矩阵理论的预测惊人地吻合。
来源:
1972年在高等研究院,高斯酉集合假设的发现建立了质数乐曲与原子核能级间的联系,这成为数学界的一个传奇故事。此传奇故事涉及数学家休·蒙哥马利(Hugh Montgomery)和杰出物理学家弗里曼·戴森(Freeman Dyson)之间的一次偶遇。蒙哥马利当时正在研究黎曼ζ函数零点的分布——特别是研究该分布相关的一种统计量,即所谓的对关联函数(pair correlation function)。数学家兼计算机科学家丹·洛克莫尔(Dan Rockmore)在他的著作《追踪黎曼假设》中描述了这次会面:
据戴森回忆,他与蒙哥马利在研究所的托儿所接送孩子时偶尔相遇,但两人并未正式被介绍过。尽管戴森名声显赫,蒙哥马利并不认为有必要去认识他。据称,当被邀请喝茶时,蒙哥马利说:“我们要谈什么呢?”尽管如此,蒙哥马利最终还是同意见面,当被介绍后,这位和善的物理学家询问了年轻数论学家关于他的工作。蒙哥马利开始阐述他近期关于对相关性(pair correlation)的研究成果,戴森打断他的话,提出了一个问题,并写下了一个具体的数学公式。“你得到了这个吗?”他问道。蒙哥马利惊讶之余几乎摔倒:戴森竟然写下了带有sinc函数的对关联函数……尽管蒙哥马利是通过数论家的路径,研究对关联函数的“质数画像”,而戴森却是通过对矩阵数学中的能级研究而得出了这一公式[2]。
译注:
休·蒙哥马利(Hugh Montgomery)是一位数学家,他研究了黎曼函数的零点分布,特别是与该分布相关的一项统计量,即被称为对相关函数的统计量。弗里曼·戴森是一位著名的物理学家和数学家,以他在量子场论、天体物理学、随机矩阵、量子力学的数学形式化、凝聚态物理学、核物理学和工程学方面的工作而闻名。
The History-Maker: Remembering Ambassador Montgomery - CIA.
Hugh Montgomery, 1st Viscount Montgomery - Wikipedia. ,1stViscountMontgomery.
对关联函数:分布函数的一个重要推广是径向分布函数 (radial distribution function; RDF),也称作成对关联函数 (pair correlationfunction),是统计力学中的一个重要概念,用Q(r)表示,其反映粒子密度在空间随与参考粒子距离的变化而变化的情况,通常可以用来研究物质的有序性或者电子的相关性。通俗来讲,径向分布函数指在某给定参考粒子周围距离r处找到另一个粒子的概率除以此处粒子的密度。
中国百科全书:
蒙哥马利和戴森的偶然发现——即控制随机矩阵和原子光谱的同一普适性规律也适用于ζ函数——得到了安德鲁·奥德利兹科(Andrew Odlyzko)自20世纪80年代以来计算工作的大量数值支持。但这一发现并不意味着质数本身受核能力驱动,也不表明原子物理实质上由质数推动;相反,它证明了谱的这一规律非常普遍,它可能是众多不同过程的自然终点,不论这些过程源自核物理学、随机矩阵模型还是数论。
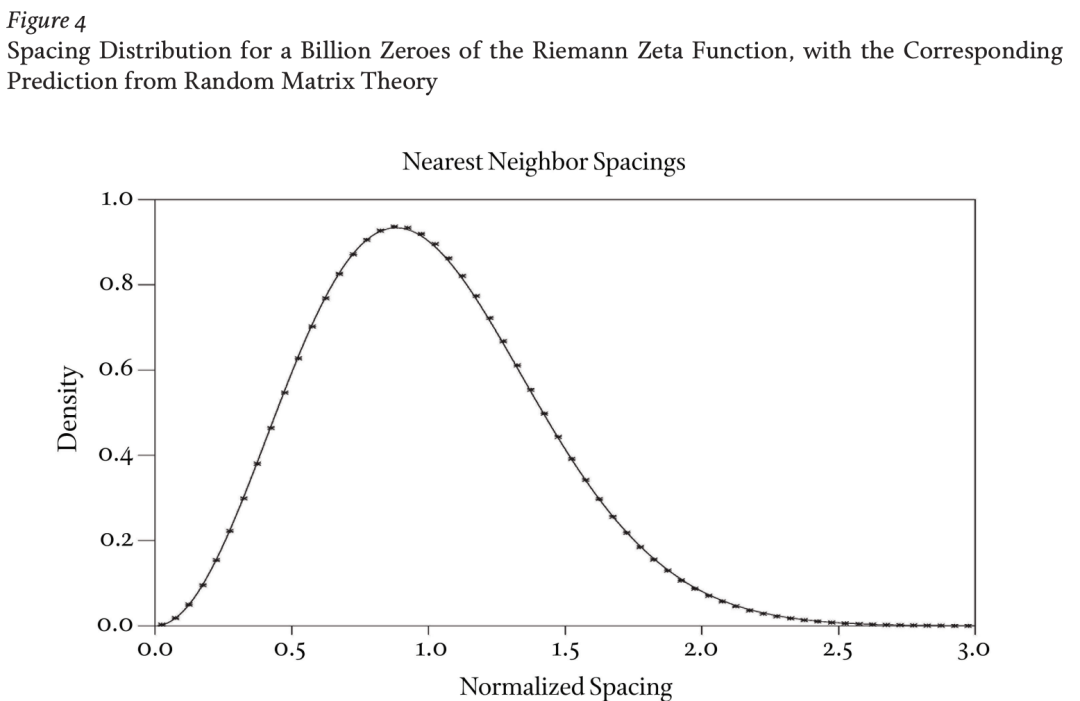
图4 . 黎曼ζ函数的十亿个零点的间距分布,以及来自随机矩阵理论的相应预测。图源:Andrew M. Odlyzko,《黎曼ζ函数的第1022个零点》,收录于《动力学、谱和算术ζ函数》,当代数学系列,第290册,编辑Machiel van Frankenhuysen和Michel L. Lapidus(美国数学学会,2001年),139-144页,~odlyzko/doc/zeta.10to22.pdf;在此获得Andrew Odlyzko的许可使用。
这个定律背后的确切机制尚未完全揭示出来;特别地,我们仍然没有一个令人信服的解释,更不用说一个严格的证明来说明为什么 ζ 函数的零点符合 GUE 假设。然而,现在已经有了大量的严谨研究(包括我自己的一些工作,以及最近几年的一些重大突破),它们显示了各种各样的随机矩阵模型(不仅仅是最著名的GUE模型)都遵守相同的间距定律,为这一假设的普适性提供了支持。目前,这些关于普适性的论证尚未扩展到数论的或者物理的设定中,但它们确实间接地支持了这一定律在这些案例中的适用性。
这些最近工作中使用的论证过于技术性,不便在此详述。但我可以提到一个关键思想,即我和同事 Van Vu 从 Jarl Lindeberg 1922年对中心极限定理的证明中汲取了灵感。从质量和弹簧系统(上文提到)的机械类比来看,核心策略是将系统中的一个弹簧替换为另一个随机选择的弹簧,并证明这样做时系统频率的分布没有显著变化。接着逐个对每个弹簧进行这种替代操作,最终能够用一个完全不同的模型来替代特定的随机矩阵模型,并且保持分布基本不变——这一方法可以用来证明,一大类随机矩阵模型有着本质上相同的分布特性。
这是一个非常活跃的研究领域;例如,与去年Van Vu和我工作同时,László Erdös、Benjamin Schlein和Horng-Tzer Yau也给出了许多其他关于随机矩阵模型普适性的证明。这个领域发展迅速,未来几年我们可能会对这个神秘的普适性规律的本质有更多的了解。
5
普适性的失效与复杂性的出现
数学和自然界还有许多其他普适性规律;我所提到的仅仅是多年来人们在动力系统、量子场论等不同领域发现的例子中的一小部分。比如,很多物理学中的宏观规律,像热力学定律或流体运动方程,本质上是非常普遍的,这使得被研究材料或流体的微观结构几乎无关紧要,除了通过一些关键性参数来描述,例如粘度、可压缩性或熵。
然而,普适性定律确实存在一定的局限。以中心极限定理为例,它预测了任何由众多小的、独立因素组合而成的数量都将趋向钟形曲线分布。但如果不满足该定理所需的前提假设,这个定律就可能不适用。比如说,所有成年人(男性和女性)的身高分布并不符合标准的钟形曲线,因为性别这一单一因素对身高的影响巨大,无法被其他所有环境和遗传因素平衡掉。
中心极限定理还有一个重要的失效场景,那就是构成某个量的独立因素并非真正独立,而是存在相关性,导致它们倾向于同涨同跌。在这样的情况下,可能形成“胖尾”现象(俗称“黑天鹅”),其数值会比中心极限定理所预测的平均值波动范围大得多。这一现象在金融模型中特别重要,在处理复杂金融工具时尤其明显,比如通过汇集抵押贷款所形成的抵押债务担保证券(CDOs)。只有在假设各个抵押贷款相互独立时,中心极限定理才能用来评估这些工具的风险;但在近期金融危机中(典型的“黑天鹅”事件),这种独立性假设戏剧性地崩溃了,导致许多持有这些证券的投资者和它们的保险公司遭受巨大财务损失。数学模型的强大仅取决于其背后的假设是否坚实。
普适性规律瓦解的第三种情形是系统没有足够的自由度来使得这些定律生效。举例来说,宇宙学家可以依据流体力学的普适性规律来描述整个星系的运动模式,然而,在仅受到三个天体引力影响的环境下,单个卫星的运动可能要复杂得多——这实际上就是所谓的火箭科学。
流体力学的普适性规律还会在介观尺度上失效:这个尺度比单分子的微观尺度要大,但又小于宏观尺度,后者是普适性规律适用的范围。一个典型的介观流体例子是流经血管的血液;构成这种液体的血细胞非常大,以至于它们不能简单地被视作微观分子的集合体,而应该被认为是具有复杂行为的介观实体。其他一些具有有趣介观特性的材料包括胶体流体(比如泥浆)、某些类型的纳米材料和量子点等;为这类材料建立准确的数学模型仍然是一个持续存在的挑战。
还有许多宏观情况,其中没有已知的普适性规律,特别是在系统中包含人类主体的情况下。股票市场就是一个很好的例子:尽管做出了极大的努力,但尚未发现能够描述股票价格变动的令人满意的普适性规律。(例如,中心极限定理似乎不是一个好的模型,如前所述。)这种缺陷的一个原因是,市场中发现的任何规律都很可能被套利者利用直到它消失。由于类似的原因,寻找宏观经济学的普适性规律似乎是一个移动目标;根据古德哈特定律(Goodhart’s law),如果经济数据中观察到的统计规律被用于政策目的,则它倾向于崩溃。(具有讽刺意味的是,古德哈特定律本身可以说是一个普适性规律的例子。)
译注:
古德哈特定律(Goodhart's law)表明,当一个度量指标成为目标时,它就不再是一个好的度量指标。它以英国经济学家查尔斯·古德哈特(Charles Goodhart)的名字命名,他在1975年的一篇关于英国货币政策的文章中表达了这个格言的核心思想。该定律反映了这样一个观点,即当一个指标被用作政策制定的目标时,它很可能失去作为度量指标的有效性。这是因为人们会开始操纵或“操弄”系统以达到目标,即使这意味着牺牲了其他重要方面的情况。
即使存在普适性规律,也可能实际上无法使用它们进行预测。例如,我们有流体运动的普适性规律,如纳维-斯托克斯方程,这些定律一直用于诸如在天气预报之类的任务。但这些方程非常复杂和不稳定,即使使用最强大的计算机,我们仍然无法准确预测未来一两周的天气。(所谓的“不稳定”,意味着即使是非常小的测量数据误差或数值计算偏差,都可能导致方程预测解出现巨大偏差。)
因此,在那些受普遍规律主导的庞大宏观系统和能够通过自然界基本法则来分析的简单系统之间,还存在一个庞大的中间领域。这些系统对于基础性分析来说过于复杂,但又不足以达到普适性的水平——简而言之,这为我们所熟悉的生活中的各种复杂性提供了广阔的空间。
尾注
[1] This essay benefited from the feedback of many readers of my blog. They commented on a draft version that (together with additional figures and links) can be read at .
[2] Dan Rockmore, Stalking the Riemann Hypothesis: The Quest to Find the Hidden Law of Prime Numbers (New York: Pantheon Books, 2005).
本文经授权转载自微信公众号“集智俱乐部”,原标题为《众里寻一:从复杂性中探索普适规律》。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}