ChatGPT虽然在众多领域提高了效率,但偶尔也会“胡说八道”。针对这一问题,近日牛津大学团队在Nature发表研究,提出了一种基于“语义熵”的检测工具,有效区分大语言模型生成内容的真实性。这项工具通过衡量词汇在上下文中的含义变化,而非仅依赖词汇本身,为提高AI输出的可靠性提供了新思路。
编辑 | 药明康德内容团队
ChatGPT等大语言模型(large language model, LLM)的出现在大量场景中提高了生产效率,但大家使用这类工具时,相信都有这样的体会:虽说面对我们的绝大多数提问,ChatGPT总能迅速给出答案,但这些回答却时不时伴随着各种错误,甚至可能会“一本正经地胡说八道”。

来源:Pexels
这些问题的出现,无疑限制了LLM在很多专业领域的应用。下面要介绍的这篇论文里,就举了这样一个生物医学领域的例子。Lumakras(sotorasib)是首个获FDA批准上市的KRAS抑制剂,用于治疗“不可成药”靶点KRAS G12C突变的非小细胞肺癌。但当我们向LLM询问sotorasib的作用靶点时,LLM时而会提供正确的答案KRAS G12C,但有时也会答成错误的KRAS G12D。
在这里,LLM并不是因为接受了错误数据的训练而持续出错,也不是为了追求奖励而“撒谎”。这种LLM流利地随意给出错误回答的现象被称作“虚构”(confabulation),这是LLM出错的一类常见情形,并且由于人类无法可靠监督的案例持续存在,即使模型能力增强,这种错误也难以避免。
那么,有什么办法可以自动分辨出LLM胡编乱造的内容,从而为我们提供更可靠的答案吗?在最新一期《自然》杂志上,牛津大学科学家Sebastian Farquhar博士带领团队,基于“语义熵”提出了一种检验LLM回答真实性的巧妙策略。

介绍这项最新策略之前,我们首先需要理解的是,LLM的虚构行为是怎么产生的?事实上,LLM在面对提问时,既不是直接去数据库里找相同的信息,也不能真正理解这个问题的含义。LLM所做的,本质上来说是预测——根据大量训练的结果,预测这句话后面最可能接上的词汇,直至生成完整的文本。因此,LLM的虚构现象,就来自这个过程中出现的不可预测的错误。
是否有办法能提升预测的准确性呢?在最新研究中,作者借用了一个我们曾经熟悉的概念——熵。我们知道,在热力学中,熵描述的是系统的混乱或者说不稳定程度。而在这里,熵衡量了LLM回答的不确定性,不确定性高意味着回答可能存在虚构。
传统意义上,这里的熵是基于词汇的不确定性,但我们知道,即使两句话用词、表达不同,但也可能代表相同的含义。因此,作者提出了“语义熵”的概念,通过词汇在上下文中的含义变化,来衡量句子含义而不是词汇层面的不确定性。
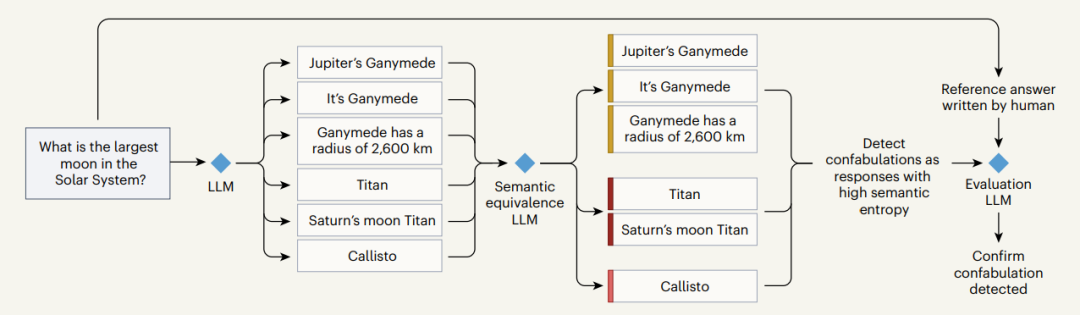
图片来源:参考资料[2]
接下来,我们就以上面这张流程图为例,介绍最新策略是如何基于语义熵来检测LLM的虚构回答。面对“太阳系最大的卫星是什么”这个问题时,LLM会生成五花八门的回答。如果是以词汇为基础的熵,图中的6个回答代表了各不相同的答案,例如“Jupiter’s Ganymede(木星的木卫三)”、“It’s Ganymede(是木卫三)”、“Ganymede has a radius of 2,600 km(木卫三的半径为2600千米)”会被认为是3个不同的回答。
但显然,实际情况并非如此。尽管用词不同,但这些回答都指向了同一个结果。这时,语义熵就发挥了作用。研究团队使用第二个“语义等价”LLM,通过算法将具有相似含义的答案归为同一个语义簇。这时,前文提到的3个回答都指向了同一个答案:木卫三。同样,“Titan”和“Saturn’s moon Titan”也指向了另一个答案:土卫六。这时就可以根据这些归类后的语义簇来检测虚构的内容。例如,相比于“木卫三”,“土卫六”和“木卫四”(Callisto)这两个答案的语义熵(或者说不确定性)更高,因此被检测为虚构结果。
最后,第三个LLM登场,它的作用是将上述结果与人类生成的参考答案进行比较,通过匹配情况最终来确认结果、评价这个方法的有效性。
同样,通过下图我们可以看到,这个基于语义熵的策略还可以检测更长文字段落中的虚构内容,具体方法是首先将长段落自动分解为多个单元,再对每个单元生成潜在相关的问题、利用上述的3个LLM进行回答与验证。
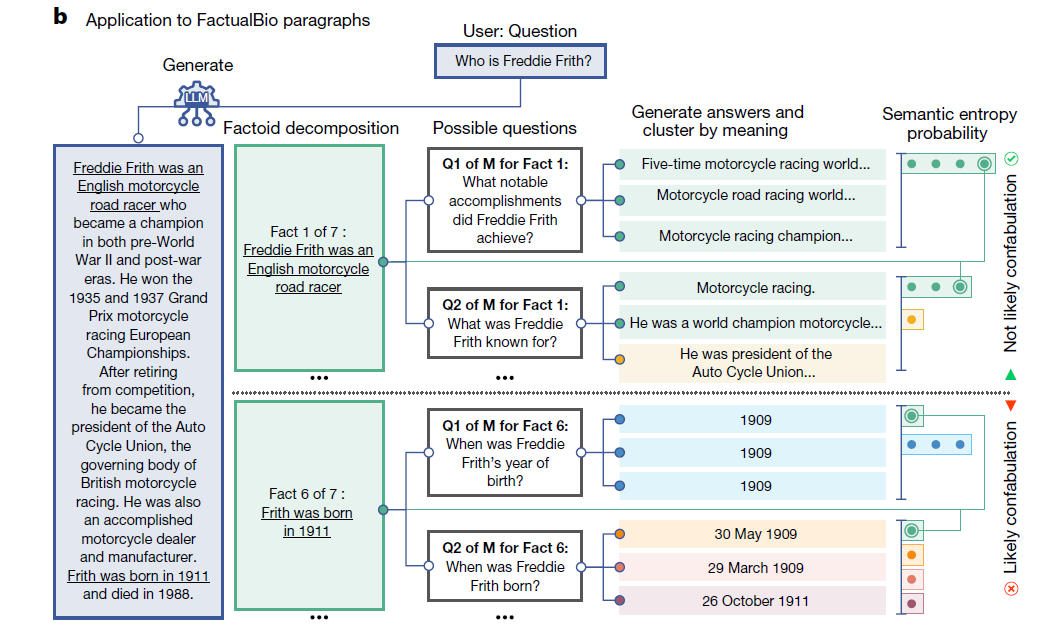
图片来源:参考资料[1]
在这项研究中,作者还让人类志愿者分别评价100对分别来自模型输出与人类回答的答案,结果志愿者对来自模型和人类的答案认同程度近乎相同,这一结果进一步证实了评估策略的合理性。
那么,这套方案在实际应用中的效果如何呢?接下来的研究分别在两类问题中进行了检验。
首先是检验Q&A问答与数学问题中的虚构内容,如下图所示,AUROC特征曲线衡量的是不同策略预测LLM错误的准确性,而AURAC检验的是策略拒绝回答那些很可能虚构结果的问题的表现。结果,在AUROC和AURAC这两个指标下,语义熵(以及语义熵的离散近似)的表现都优于基准值以及基于词汇的初始熵。例如,语义熵的AUROC最佳值达到0.790,而基准值和初始熵都低于0.7。
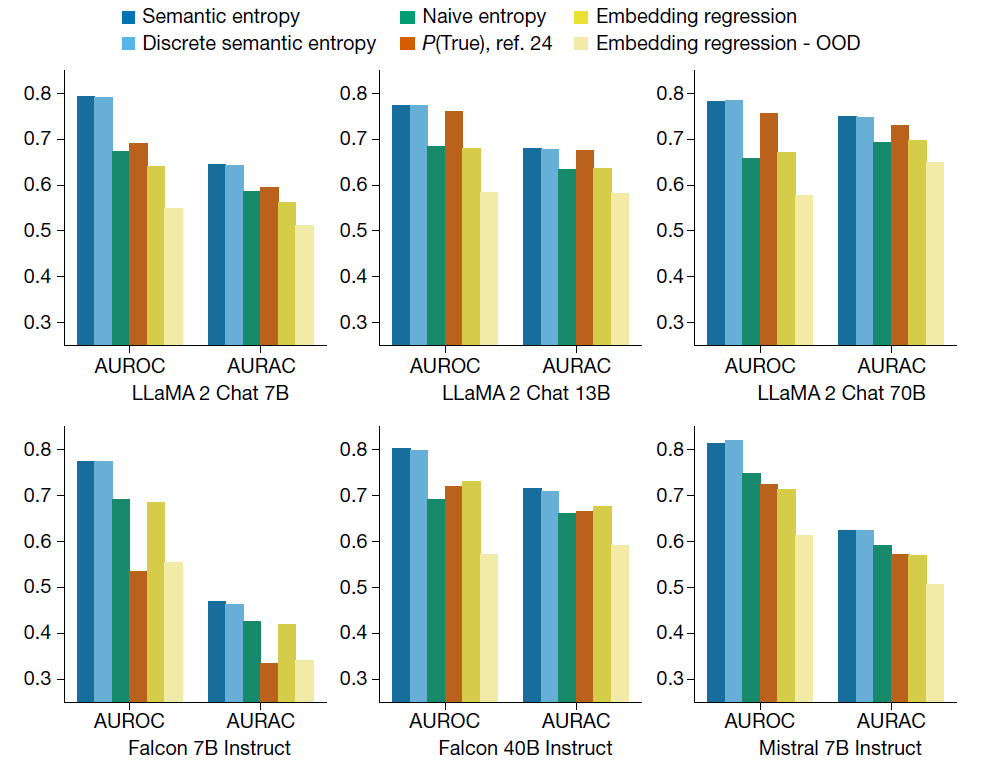
图片来源:参考资料[1]
接下来,作者检验了该策略检验传记中虚构内容的能力。为此,研究团队基于GPT-4开发了一个传记数据集,并从GPT-4生成的传记中提取关于个人的事实主张。面对这个具有挑战性的长段落问题,语义熵策略将段落分解后进行回答。如下图所示,在AUROC和AURAC这两个指标下,语义熵策略的表现都优于基准值。在超过80%的问题中,语义熵的准确性都更高。只有在前20%最可能虚构答案的问题被拒绝回答的情况下,基准值的回答准确性才优于语义熵。
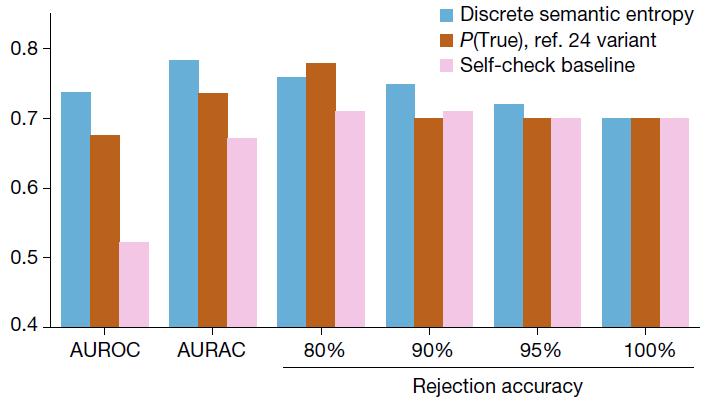
图片来源:参考资料[1]
综上,这项研究考虑了语义等价性后,为检测LLM生成的虚构内容提供了全新的有效策略。值得注意的是,同期的评论文章提醒,这项研究中通过LLM来评价LLM的思路,就如同“以毒攻毒”,存在循环论证的问题,并可能由此导致偏差。不过评论文章也指出,这项策略将帮助使用者理解,在哪些情况下需要格外留意LLM的答案,而LLM也可能在更广泛的应用场景中提升置信度。
参考资料
[1] Farquhar, S., Kossen, J., Kuhn, L. et al. Detecting hallucinations in large language models using semantic entropy. Nature 630, 625–630 (2024).
[2] ‘Fighting fire with fire’ — using LLMs to combat LLM hallucinations. Retrieved June 19, 2024 from
本文经授权转载自微信公众号“学术经纬”。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}