最近电视剧《狂飙》火爆全网,剧中后期出现大量配音的情况——演员口型和声音对不上。因此许多观众研读“唇语”一探究竟。实际上,在AI蓬勃发展的今天已经出现了“唇语识别”,这也是语音识别的应用之一,它能够帮助你发现“真相”。
演讲 | 山世光(中国科学院计算技术研究所研究员)
1997年我大四,因为是本硕连读,做本科毕业设计的同时要选择未来的研究方向。于是我去问我导师:“我以后该做什么方向呢?”
他说:“这个问题不能问我呀?得问自己。我们做计算机应用,或者是说让计算机像人一样智能,得让计算机具备看、听、说、写的能力,简单的说就是声、图、文。你想做什么,对什么感兴趣?”
我想了想,说:“图像很好玩,看的见、摸的着。”所以我就选择了“图”。
那做图像、做视觉,具体是做什么呢?我当时的导师跟我说:“我认人的能力不太行,经常上次见了一个领导,下次见面还是叫不出名字,挺尴尬的。能不能做一副眼镜,上面装个摄像头,每次见到一个人就记录下来,下一次见到就不会记不起他的名字了。”
我觉得这对我也挺好,因为我也记不住人脸,所以我说:“那我就去做人脸识别吧。”于是,我就在做本科毕业设计的时候开始做人脸识别,即根据摄像头拍摄的照片判断一个人是张三还是李四。我一做就做了20年,一直做到了2017年。那2017年发生了什么事情呢?
大概在5年前,我在一次演讲中说:“现在在座的每年刷脸的次数是个位数,但我相信再过个三五年,大家每天刷脸的次数应该有几十次,或者是更多。”现在事实上已经是这样了。为什么呢?因为大概在2015年到2017年,人脸识别的技术有了一次跨越式的发展。这对我这样一个从1997年就开始做人脸识别的人来说,都有点出乎意料。

在2010年之前,人脸识别系统错误率是1/1000,即比对1000次就可能会错1次。到了2017-2018年,这个错误率降到了百万分之一,也就是比对100万次才会错1次,这在10年前我认为这是不可能的。
所以当时我对自己特别失望,为什么自己做人脸识别这么多年后,脑子反而好像变笨了,连这都预测不到。后来我给自己找了个借口:其实这件事情不是那么容易预测的。技术的发展经常会出乎我们的意料,所以不要固步自封,不要按照自己的固有的知识经验,认为一个技术不会发展得那么快。这对我后面的很多研究方向的选择,也带来了一些非常好的启发。我不会再那么保守,很多时候需要放开眼睛去看。
所以到了2017年前后,我面临着一个很严峻的问题。之前我觉得选择人脸识别这个方向挺好,做到退休也不会失业。结果到了2017年,才20年,我就要失业了。因为人脸识别已经做到了百万分之一、千万分之一的错误率,后面真的就没什么可做的了。难道我这就要退休吗?我想了想:“这不行,要再想想该干点什么。
我原来认人的能力不行,那现在有什么毛病呢?我察言观色的能力不行。比如跟别人聊天,别人心里到底想什么,我老是猜不出来。那机器能不能帮我做点事?”

马库斯·图留斯·西塞罗(Marcus Tullius Cicero)
西塞罗有一句名言:“世间一切尽在脸上。”其实我们在脸上能够看到的信息,远远不止“他是谁”“他是男是女”“他20岁还是80岁”……我们能看到很多,他所经历的人生沧桑、他的愉悦、他的过去,也能够看到他现在可能在想什么,是很高兴、很伤心、还是很无聊。
我们能够看到的信息好像非常得多,所以我想:“也许这个时代,很快要从过去看脸的时代变成读心的时代。”
从脸上读出你的生理指标
什么叫读心呢?我给它下了一个定义。就是根据一个人外显的语言和行为,去推测他内心的心理和精神状态。

那再仔细分析,其实还有不同的层次。最底层是相对比较客观的生理指标,比如心率是多少,每分钟呼吸多少次,或者说每分钟眨多少次眼睛,血压是多少等等。
然后中间层是心理状态,主要就是情绪,比如喜怒哀乐、疲惫、亢奋、紧张等等一些中期的心理状态。
再往上走,可能就体现一个人的人格、精神状况等方面,特别是一些跟精神卫生相关的,比如自闭症等一些精神性的疾病。这就变得相对越来越主观了。
先来看一下生理指标。如果我们想通过一个在半米到1.5米距离内的普通摄像头,拍摄一个人的视频,然后用算法去估计下图中的指标,可能吗?
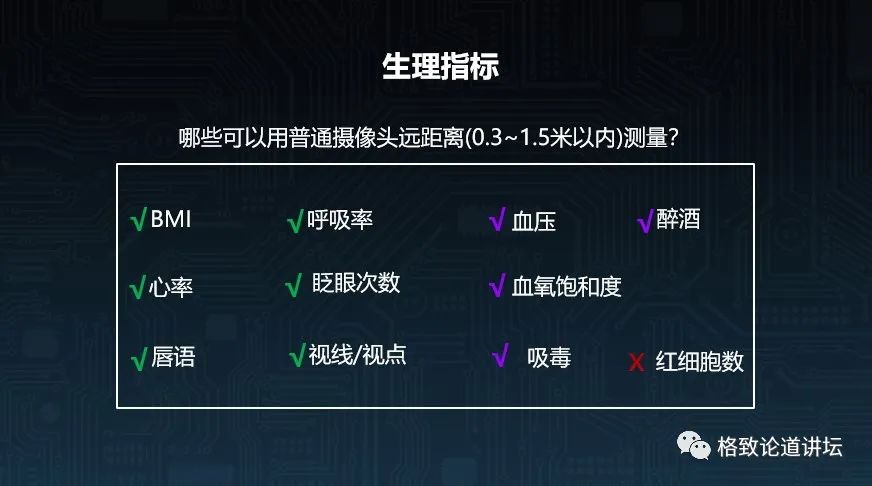
眨眼次数应该是比较容易的一件事情,但如果是呼吸率,能不能行呢?能不能在听不见声音的时候,通过嘴唇理解我现在在说什么呢?
图上打对号的,其实都是可以通过一个普通的摄像头逐渐实现的,但是到目前为止,我还没有看到可以通过摄像头测量血液里红细胞数量的技术。
而血压、血氧饱和度,我过去也觉得不行,但我现在思想更加开放,认为在严格的光照采集条件下,是可以用普通的摄像头加一个算法进行估计的,所以我们也在努力做这件事。还包括醉酒,现在也已经有一些可以做的基础技术了。比如一家做共享汽车的公司,它不能让一个醉汉去开车,那就能通过摄像的方式来评估司机是不是醉酒了。
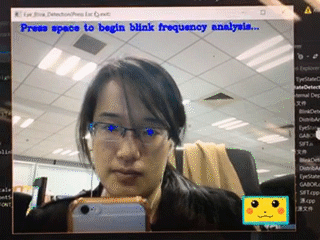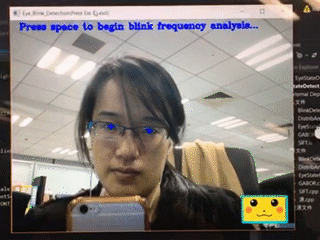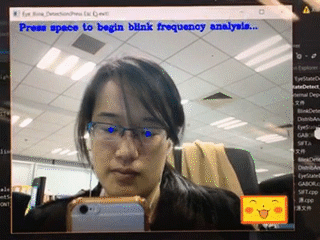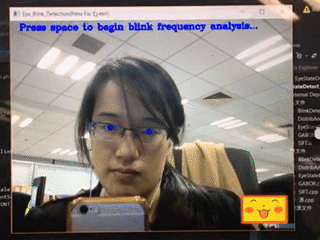
上图给大家展示的是对眨眼的评估。这个其实非常容易,只需要让算法找到眼睛,然后判断眼睛的状态是睁开的还是闭上的,并时刻关注、评估这样的状态,就可以估计出这个人每分钟眨多少次眼睛。比如一个人紧张的时候,眨眼的次数可能就会控制不住地增多,所以这也是一个非常重要的体现心理的指标。
那身高体重可不可以评估呢?如果拍一张全身照去估计身高、体重是可以的,但如果只有一张面部的照片能不能估计呢?
我们在去年(2020年)收集了3000多人的数据,然后用一张脸部照片去估计身高、体重以及BMI指数。我们发现误差还行,比如身高的误差大概在5厘米,体重的误差大概在5公斤,BMI指数误差不到2。这样的误差,已经远远比人通过照片估计身高体重和BMI要小得多了。

我现在站在这里,大家看着我肯定估计不出来我现在的心率是多少,我的心脏每分钟跳多少次。我现在可能很紧张,可能每分钟跳100次,可是你看不出来。
但是我们用一个摄像头拍摄10秒钟的视频,就可以比较准确的估计出一个人的心率是多少。下图中黄色的数字是用专业设备测量出来的心率,红色的就是用一段视频估计出来的。
这项技术已经放到了华为的智慧健康APP里面,只需要看着摄像头10秒钟,就可以估计出你的心率,误差大概只有3次。
这些看起来不可能的事情为什么可以做到?其实只要仔细想想,会发现这背后其实是有非常清晰的科学逻辑的。

放大的脸部颜色周期性变化
因为心脏在跳动的时候会泵血,所以血流量在血管里会有周期性的多、少的变化。这样的一个变化在皮肤的毛细血管里面也会有,从而导致皮肤上反射的不同颜色光的强度也会有周期性的变化,所以我们只需要捕捉视频中非常微弱的颜色的周期性变化,就可以把心率估计出来 。
那类似的血压、血氧饱和度等,我们也可以通过分析颜色进行处理,最终就有可能可以估计出来。我们现在正在做这样的技术,虽然不能说一定可以做到非常准,但是已经可以看到是有可能的。
另外一件非常重要的事情是什么呢?暗送秋波:人在看什么地方,在看谁,其实也反映了非常非常多重要的信息。所以视线估计或者说视点估计,也是一个非常重要的技术。
从视频里大家可以非常明确的看到,摄像头前面的一个人在看哪里,这也是我们现在已经能做到的程度。
我们希望做到一些应用,比如判断驾驶员在转弯的时候有没有看后视镜,或者在开车的时候有没有目视前方等等。
可辅助、甚至取代语音识别的唇语识别
刚才提到唇读。听不见声音的情况下,我们能不能根据嘴唇的信息来估计这个人在说什么?
唇语识别研究的起源有一个故事。

就是2006年世界杯上,马特拉齐好像说了一句话把齐达内给惹怒了,然后齐达内就用头撞了马特拉齐。事后大家都在猜他到底说了什么把齐达内惹怒了,于是就有很多人通过唇读技术研究。
唇读其实是可能的。我们知道,社会上有一群弱势群体——聋人,他们在跟正常人交流的时候就非常需要这样的技术。他们每个人都在聋校里面锻炼了这样一种能力,可以通过读唇读出大概百分之七八十我们的话。
那我们就想,是不是可以让AI具备这样的能力。
事实上,我们现在也已经做到了。比如在车里开车的时候,外面的噪声特别大,或者是发动机的声音特别吵的时候,声音的识别可能就失效了。在这个情况下,AI对唇语的识别可以达到90%以上的精度。
为了做这件事情,我们还发布了全球规模最大的中文唇语识别数据集,采集了超过2000人的70多万个样本。

还有一个非常有意思的发现,即做唇语识别不能只看嘴唇,还要看全脸。为什么呢?因为我们有会说话的眼睛。
我们的眼睛、下巴、腮部的这些肌肉也会受到说话时的影响,所以我们发现用全脸的信息而不止是嘴唇的信息去做唇语识别,会有更高的精度。
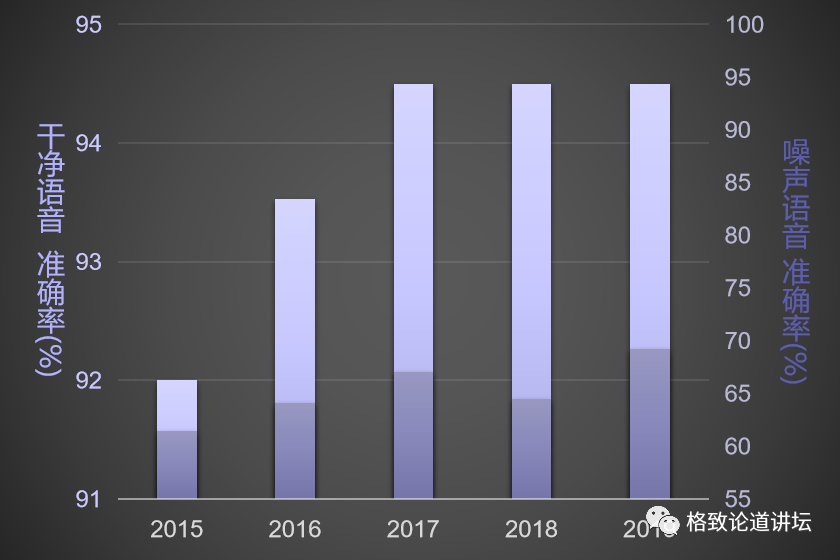
高噪声环境下,传统的语音识别的准确率大大降低
那唇语识别能帮助我们做什么?刚才提到了聋人需要这样的技术,可以帮助聋人知道普通人在说什么,促进和正常人的之间的交流。其实对于普通人,在噪声特别重的情况下,语音识别也会失效,那就可以配合上唇语识别去得到更高的精度。

矫正发音唇形
同时它也提供了一个渠道,用来帮助我们学英语或者学不同语言的时候,进行唇形的矫正。还有一些特殊的场景,如通过唇语来下达指令,进行密语的通讯等等,这都是可以用上的场景。
感知你我的喜怒哀乐
前面介绍的几个技术,都还是底层的生理指标。那么AI算法可不可以感知到人的喜怒哀乐,即开展心理状态的估计呢?
这里涉及到的技术就更多关系到对表情、面部肌肉的动作、微表情以及各种各样的心理状态的识别,比如看看是困了、疲倦了,还是亢奋、激情满满等等。
这方面的一些技术,学术界已经研究了很多年。最主要或者最常见的就是把人的情绪分成7类基本表情,如喜、怒、哀、乐等,学术界也达到了85%甚至90%的正确率。
中性、生气、厌恶、害怕、高兴、伤心、惊讶这7种基本表情的图像集上,识别准确率>85%。但这显然不够,人的情绪是非常复杂的,所以后来出现了很多更加复杂的去描述情绪的一些模型。
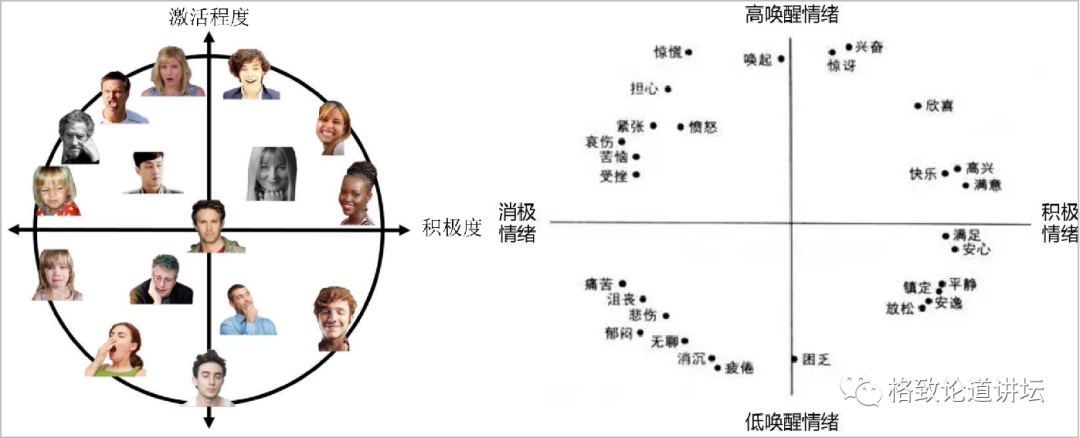
Hanjalic的激活度和愉悦度情绪模型
比如说Hanjalic提出的激活度和愉悦度的情绪模型。一方面是看这个人的唤醒程度,他是亢奋,还是无精打采?另外一个维度就是看他的情绪是正向的,还是负向的?这样就可以把更多的情绪建模进来。
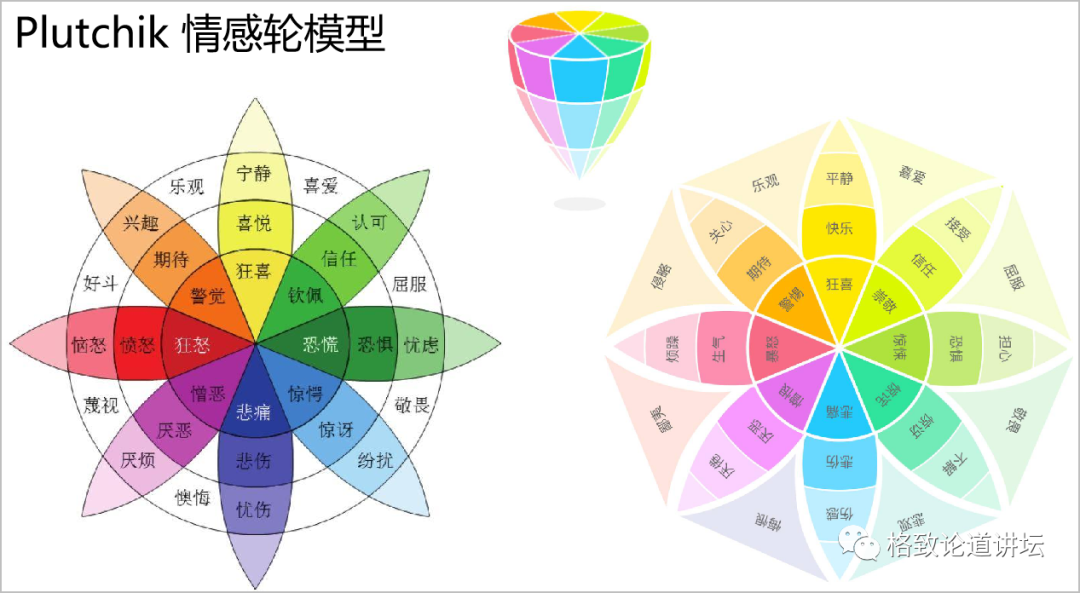
Plutchik的情感轮模型
Plutchik还提出一个情感轮模型,能更好地把人的各种各样复杂的情感建模进去。那做AI算法的时候,我们就希望能让AI算法自动地评估更加复杂的情感。
但是我们知道,其实如果只是通过“看”来分析一个人的情感,也不是那么容易。所以通过声音、手势、文字等等多种模态融合去做人情绪感知也变得更加重要。
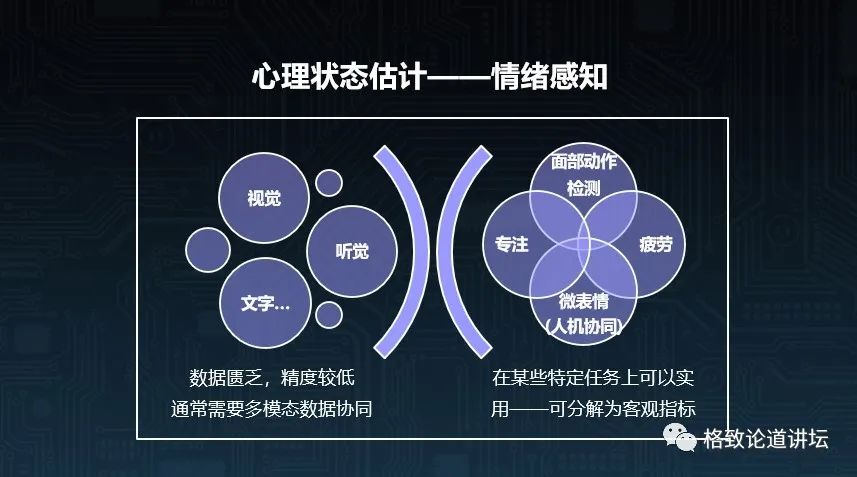
那么,在表情识别技术还不成熟的情况下,是不是就不能做应用了呢?事实上,在一些特定的任务上还是可以做的,特别是一些可以分解成客观指标的情绪感知技术。

比如我们可以去监测一个人面部各种不同的动作。事实上心理学家定义了40多种面部动作,比如嘴角上扬、皱眉等等,其中有20多种是可以通过摄像头捕捉的。
当检测到了一个动作,亮条就会往右走一下。
大家可能看过《别对我说谎》(Lie to me)这个电视剧,这里面就体现了我们称之为微表情的技术。

所谓微表情,就是在非常短可能只有五分之一秒的时间里呈现出来,然后马上消失的一个表情,它更能反映人内心真实的情绪。
现在通过人和机器的协同分析,是可以对一个人想压抑住的一个非常短暂的表情或者是情绪进行正确感知的。
下面是另外一个可以客观化的心理状态——疲劳。比如开车的时候,如果已经非常困了,那就会非常危险。我们就可以通过分析其眨眼次数、每次眨眼时闭眼的时长、打哈欠的次数、头部姿态的变化,包括视线方向和心率等等一些生理指标去对其疲劳状态进行评估。
还有一个很有意思的技术,就是可以对一个人做事情的专注度进行评估。
在2018年我们参加了一场国际竞赛,还拿到了第二名。我们把一个人分神的状态分成四个等级:0是特别分神,3是特别专注。然后我们得到的评估精度可以达到0.07,误差非常小。过程中我们也是先把它分解成了视线、头部、面部的动作等生理指标,然后综合评估一个人分神的状态。
AI“相面”:对精神状况的评估与诊断
最后就是关于精神状况的评估,其实大家日常也是经常会遇到的。比如碰到一个人,可能我们对他会有所谓的第一印象。第一印象其实就是我们对一个人人格特质的观察,或者是我们对他的认知。

在去年6月份的Scientific Reports上就刊登了这样一件事。几个俄罗斯人找了一万多人每人三张面部的照片,然后分析他们五种不同的人格特质,即所谓的大五人格。这非常像相面,虽然存在伦理问题,但也反映出人格的特质和长相之间有一定的相关性。右侧给出了偏外向比较亲和的,以及相对不太亲和的男性和女性会偏向的长相。
此外,在精神卫生科有非常多的疾病,目前都要靠医生做出主观的判断。可是不同的医生可能由于经验的不足或不同,会给出不一样的判断。所以我们也希望在这个过程中逐渐地做一些客观化。
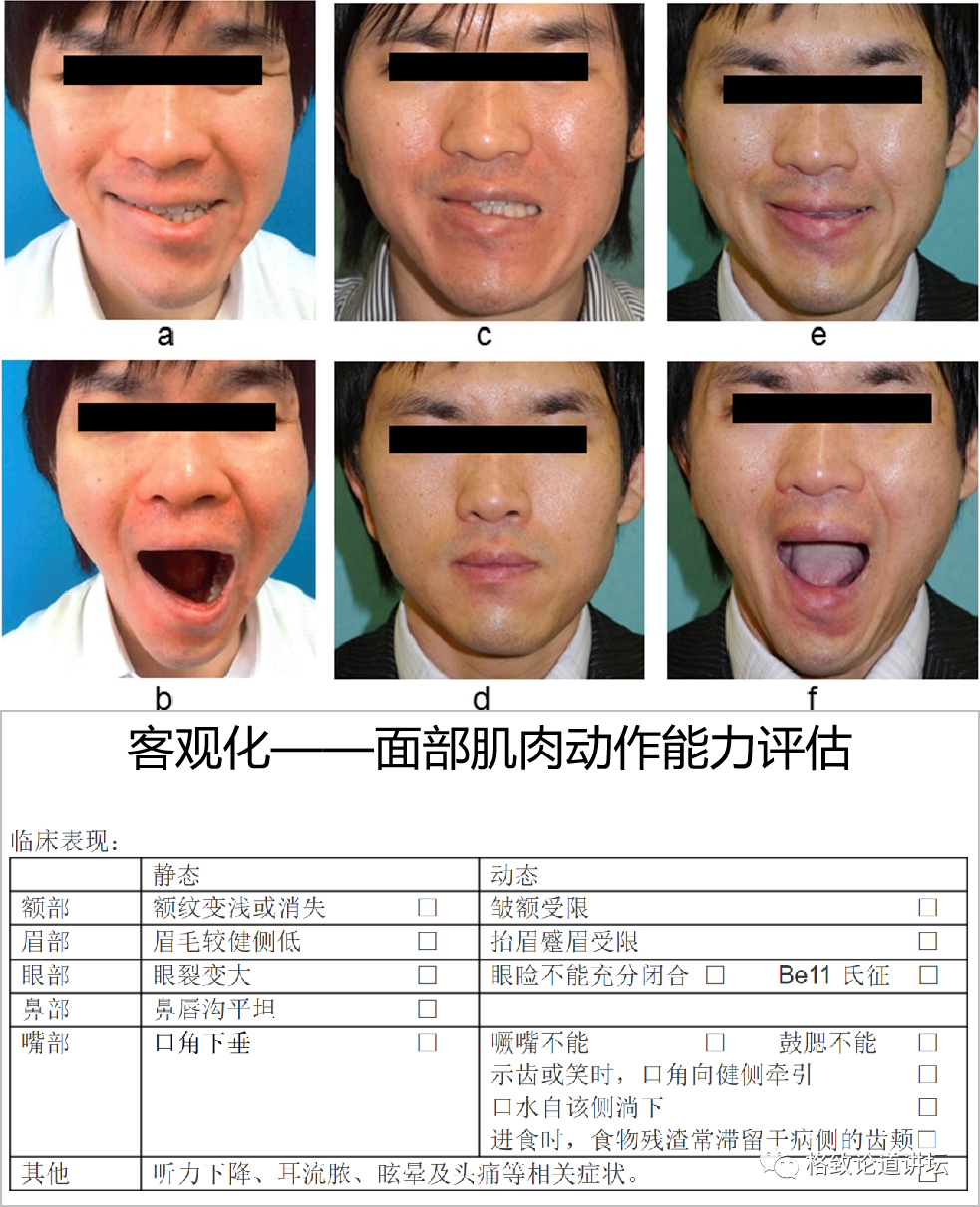
比如面瘫。面瘫其实就是面部的神经出了一些问题,所以有些面部动作就会做得不够精确。医生就需要一套系统去评估面部神经或者面部肌肉动作的能力。这就可以用摄像头去捕捉,并进行客观的评估。比如张嘴的时候是不是能够张得足够开,做某一个动作时候能不能做到。

精神状况——抑郁症检测与评估
来源:Sharifa Alghowinem, Roland Goecke, Michael Wagner, Julien Epps,Matthew Hyett, Gordon Parker, and Michael Breakspear. Multimodal DepressionDetection: Fusion Analysis of Paralinguistic, Head Pose and Eye Gaze Behaviors. IEEE T on AffectiveComputing. 10-12 2018
这是澳大利亚几所大学在2018年联合做的一项工作——通过对抑郁症病人一段视频里面的视觉特征和语音特征联合进行分析。用到的特征包括说话的方式、在说话过程中头部姿态的变化以及眼神等。
如果只用语言的特征对重度抑郁和健康人进行分类,可以达到83%的正确率,只用头部姿态可以达到63%的精度,只用眼神可以达到73%的精度,而合起来则可以达到88%的精度。
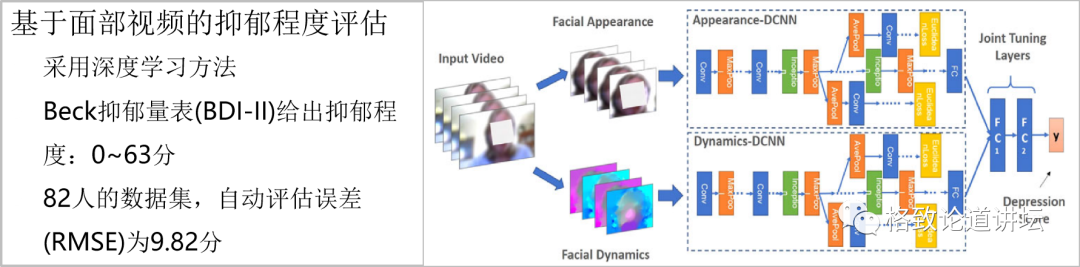
精神状况——抑郁症检测与评估
来源:Y. Zhu, Y. Shang, Z. Shao, and G. Guo. Automated DepressionDiagnosis Based on Deep Networks to Encode Facial Appearance and Dynamics. IEEET on Affective Computing, 2018
这是美国西弗吉尼亚大学学者的另外一个工作。他们通过深度学习,对一个人的一段采访视频进行分析,然后评估他的抑郁程度。
0分是完全没有抑郁,63分是重度抑郁,最后他们得到的误差是9.82分。比如一个人是20分的抑郁程度,给出来的结果能在11到29之间,说明这个精度也还可以了。
另外,儿童的自闭症也是一个非常严重的社会问题,大家知道社会上自闭症儿童的发病率是多少吗?美国2020年的数据是五十四分之一,即每54个小孩中就有1个是自闭症。
在中国这个数据大概是一百四十分之一,即140个儿童里面就会有1个是自闭症。严重的自闭症儿童很可能终身都不能够生活自理,但是如果能够早发现、早干预,那么很可能可以使他成年之后能够生活自理。
目前自闭症儿童的诊断方式是让一个经过认证的医生和一个小孩玩45分钟,并在这个过程中按照美国的一套ADOS标准进行打分,然后才能够判断出来是不是自闭症。
那有没有可能用AI技术更好地去做这件事情,更客观快速地进行评估?于是我们设计了新的流程,希望能够把过去的45分钟变成5-10分钟。
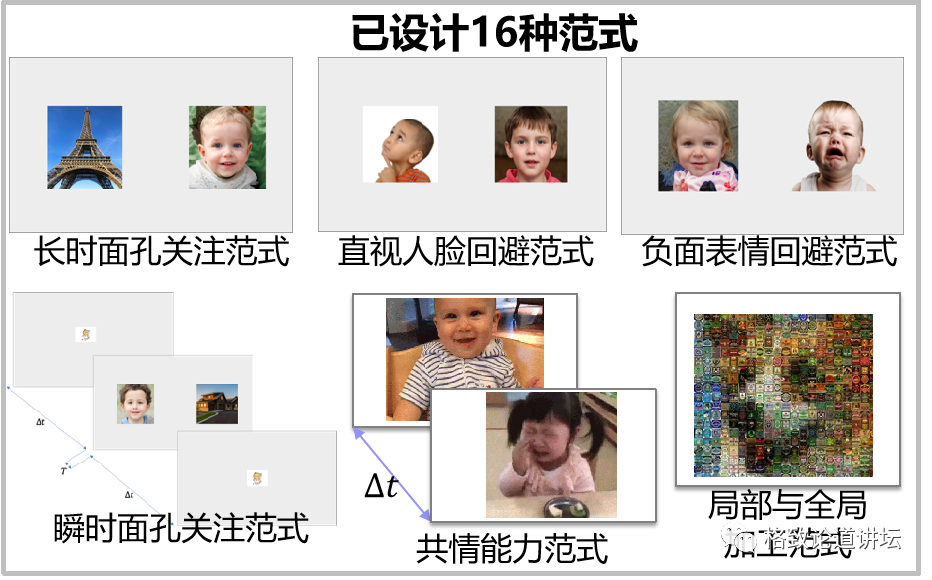
首先我们会让小孩看5分钟设计好模式的动画片,或者一些实验好的范式,现今我们已设计16种范式。
一个是实验是让孩子看同时出现人和车的视频,观察他会不会更多地关注人。
然后在这个过程中,我们用视点估计的技术去测量他的视觉偏好,比如他喜欢看什么地方。然后看他的表情,看他是不是有足够好的共情能力,看他的行为是不是有正常的社交偏好。
我们现在正在开发这样的技术,也已经采集了很多正常小孩和自闭症儿童的数据。我们希望能够在未来开发出这样的系统,通过让一个小孩看5-10分钟的视频,就能够得出他患自闭症的可能性。
我刚才回顾了一下自己的研究历史,我觉得作为科技工作者,做什么样的技术,很多时候应该要考虑对什么感兴趣,但是同时也要去关注什么样的技术是社会所需要的。
比如有关自闭症儿童的这件事,就非常需要用AI的技术来帮助医生更加快速的去筛查,找到可能的自闭症儿童,这对于社会的发展和进步是非常重要的。
谢谢大家。
本文经授权转载自微信公众号“格致论道讲坛”。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}