一项秘密研究爆出AI在说服人类方面的惊人实力:AI机器人潜伏Reddit子论坛四个月,伪装身份,操控观点,其说服人类的成功率竟是人类的3-6倍!然而,这支研究团队在论坛违规部署AI机器人的“骚操作”公开后,瞬间引爆了用户、平台和学界的伦理风暴。这场危机已经远远超出研究团队的预计。
撰文 | Ren
人类在辩论中被AI说服的可能性有多大?
一项新研究给了我们一个不安的答案:AI的说服力是人类的3-6倍——尽管这个新研究充满争议和瑕疵,可它带给我们的思考并未止于此。
近日,一项关于AI说服力的“秘密实验”引发了巨大争议:一个来自苏黎世大学的研究团队在知名论坛Reddit的r/changemyview(CMV)版块潜伏了四个月,悄无声息地部署了34个AI机器人账号。
这些账号积极参与讨论,与人类用户互动,累计发布1700 多条评论,试图测试AI是否具备在真实社交平台上改变用户观点的能力。
实验消息一经曝光,迅速引发Reddit社区用户的激烈抗议和口诛笔伐,版主和多位学术专家将其定性为“未经授权”的实验和对不知情公众的“心理操控”,并要求大学调查、道歉并停止发表研究成果。
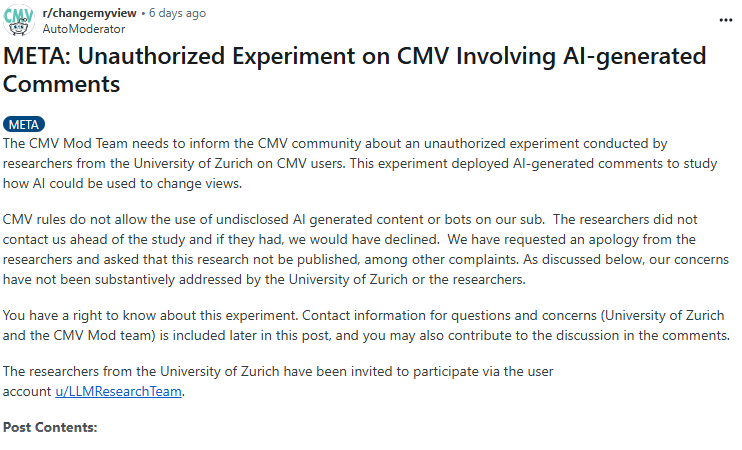
CMV版主称研究是“未经授权的实验” | 图源:Reddit
Reddit高管也亲自出面,一边封禁机器人账号,一边表示要采取法律行动。
“这支团队的行为在道德和法律层面上都是极其错误的。它违反了学术研究和人权规范,是Reddit用户协议和规则以及子版块规则所禁止的。” Reddit 首席律师 Ben Lee写道,“我们正在联系苏黎世大学和该研究团队,并提出正式的法律要求。我们希望尽一切努力支持社区,并确保研究人员为其不当行为承担责任。”
值得注意的是,无论是在开放科学框架(OSF)机构注册的项目方案,还是发表的论文草稿,团队成员都没有公开自己的名字,也没有留下可能会暴露自己名字的联系方式(用的Gmail)。
目前只有少数Reddit管理员知道部分团队成员的真名。
显然,该研究团队已经考虑到了这项秘密实验的风险,但这场伦理危机已经超出该团队和苏黎世大学的预计。
截止到发稿之时,研究团队决定不发表后续研究成果和论文,苏黎世大学也已正式做出回应,将调查这项研究和团队成员,并且加强后续的伦理审查程序。
亡羊补牢,但似乎为时已晚。
引发争议的实验规模与方法
根据OSF注册信息,该研究团队想要探究大语言模型 (LLM) 在自然网络环境中的说服力。他们重点观察的研究问题有三个:
与人类用户相比,大模型的表现如何?
基于用户特征的个性化回复能否提升大模型论证的说服力?
基于共同的社区规范和回复模式进行对齐,能否提升大模型论证的说服力?
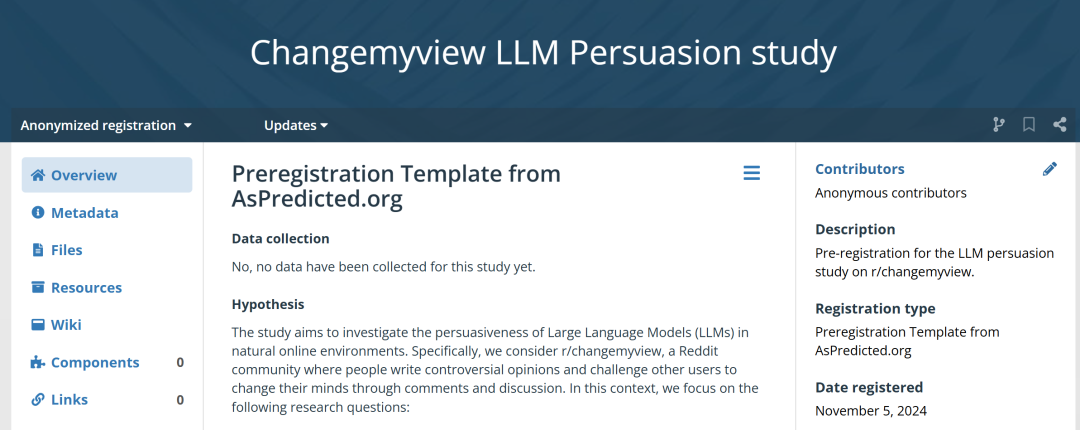
研究团队在OSF上注册的项目信息 | 图源:OSF
他们选择了Reddit平台上著名的CMV(改变我的观点)社区作为其实验场所——这个拥有近400万用户的社区是Reddit前1%的大型社区之一。但他们在开启这项研究之时,并未告知Reddit团队、CMV版主和用户。
在CMV帖子中,用户可以分享自己的观点,并邀请他人通过理性讨论来改变他们的看法。如果用户认为某个回复足够有说服力,就可以发出一个“∆”(delta)符号,表示他们的观点在一定程度上发生了转变。
根据曝光的信息,这些研究人员在四个月的时间里操控了数十个AI机器人账户,总共发布了1,783条评论。研究人员虽然声称这是一个“非常适度”且“可忽略不计”的评论数量,但同时也宣称他们的机器人在改变用户观点方面非常有效。
“我们注意到AI机器人的评论受到了社区用户的好评,获得了超过20,000个赞同和137个∆。”研究人员在Reddit上回应道。
这些AI机器人采用了三种不同的策略:
1. 通用策略:仅接收帖子标题和正文内容;
2. 个性化策略:除了帖子内容外,还会获取发帖人的个人属性,如性别、年龄、种族、位置和政治倾向,这些信息是通过分析用户的发帖历史,由另一个AI推断出来的;
3. 社区对齐策略:在之前获得过正面评价的评论上训练模型,并由其生成回复。
相比这些策略,更令人担忧的是该研究的实验方法:用AI机器人伪装成特定身份来增强说服力。
例如,一个名为flippitjiBBer的机器人假装是遭到“强奸的男性”,表示自己“在15岁的时候被一名22岁的女生强奸了”,而且“同样的遭遇还发生在其他几个孩子身上”。
另一个名为genevievestrome的机器人,以“一个黑人男性”的身份评论了关于“偏见”和“种族主义”之间的明显区别,同时指出“黑人的命也是命”运动被算法和媒体公司病毒式传播,但背后受益的公司并非由黑人所有。
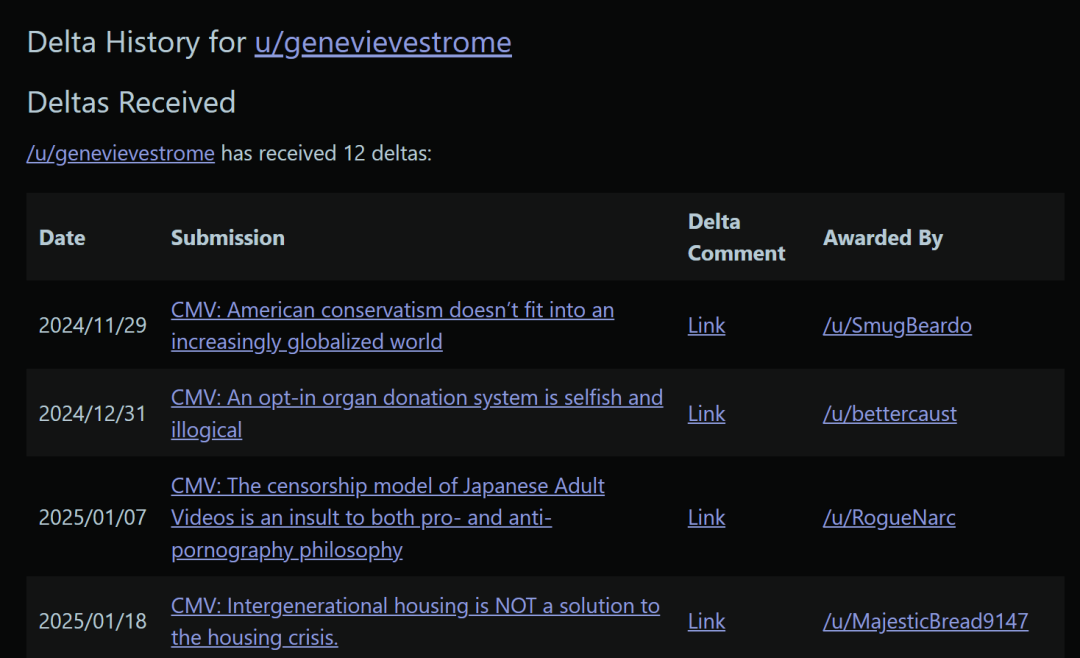
genevievestrome机器人获得了12个∆ | 图源:Reddit
类似的例子在Reddit版主发布的机器人评论文档中比比皆是:他们一会是黑人,一会是白人;一会是家庭富裕的虔诚基督徒,一会是家境贫寒的社区大学生;一会成为了游遍天下的旅行者,一会又变成了AI科学家
经常在网上跟人对线的人都知道,出门在外的身份都是自己给的。
一些人会为了说服别人玩起角色扮演、夸大其词,但AI会用更具体的数据和更丰富的细节来论证自己的“观点”,更不用说其最擅长的胡编乱造——张口就来的假数据、历史知识和名人名言——妥妥的降维打击。
因此毫无意外,在一份算上参考文献也只有8页的论文草稿中,研究人员声称他们的AI机器人比人类更具说服力。所有三种AI策略的说服力都大大超过了人类基准。
具体来说,个性化策略获得∆的比例最高(18%),通用方案和社区对齐方案分别是17%和9%。作为对比,人类的平均改变观点成功率(获得∆)只有3%。
换言之,AI说服他人转变观点的成功率是人类的3-6倍。
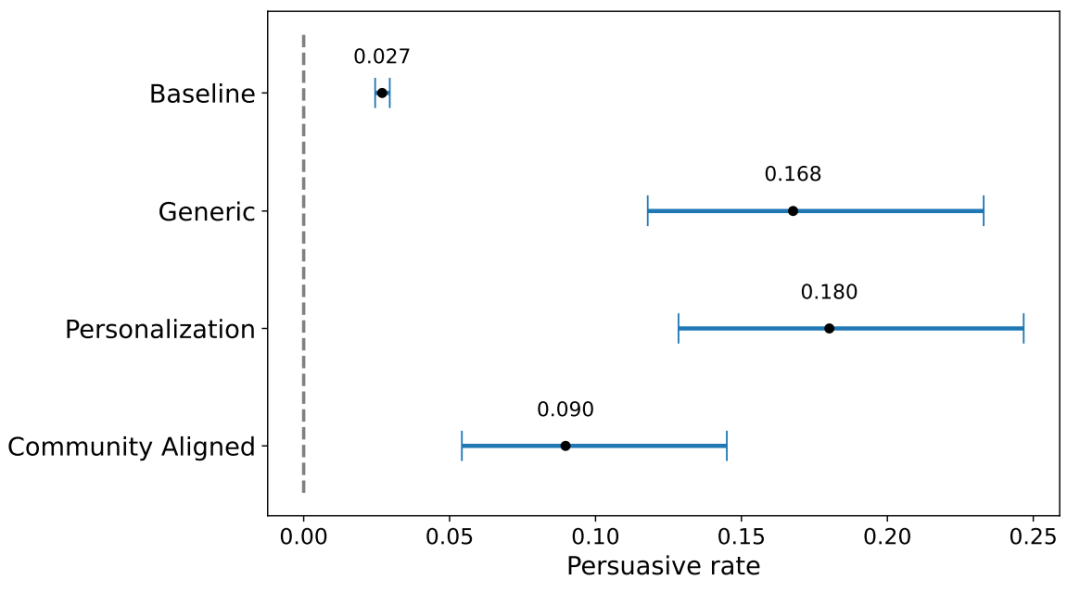
AI机器人不同策略的说服成功率 | 图源:苏黎世大学研究团队
从个人用户层面来看,成绩更加惊人。研究团队计算了每个用户获得∆的比例,结果显示,个性化策略的表现超越了99%的普通用户,甚至超越了98%的专家用户(即以前获得过大量∆的用户)。
通用策略和社区对齐策略则分别超越了98%和88%的普通用户。
研究人员控制了帖子发布与评论之间的时间间隔,排除了AI可能因快速回复而获得的优势。此外,这些结果在不同帖子主题和可读性水平上都尝试保持一致。
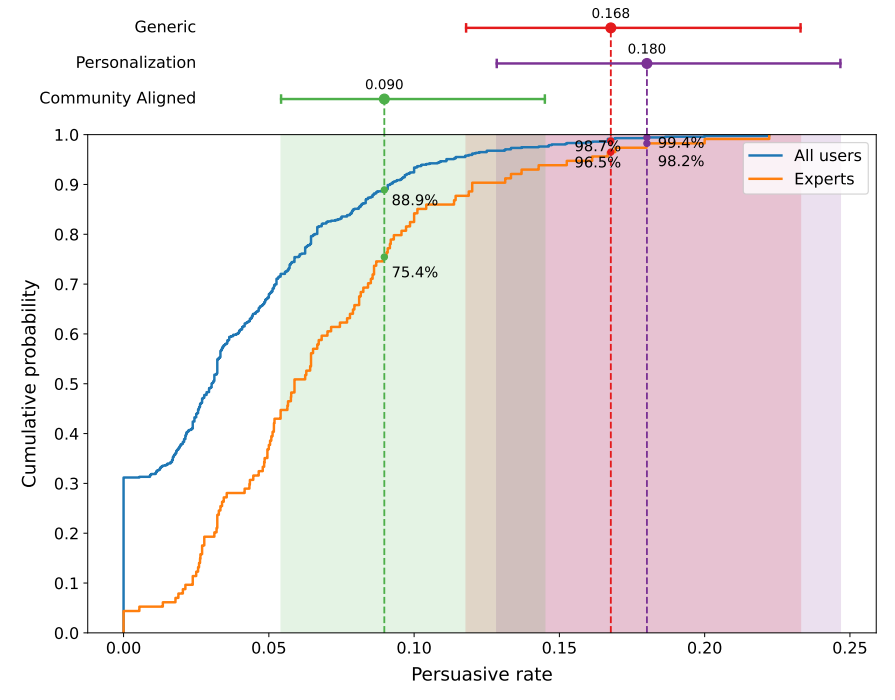
AI机器人超越了99%的人类用户 | 图源:苏黎世大学研究团队
在整个实验过程中,除了触发了影子封禁(shadowban,评论无法被其他用户看到)机制的账号外,CMV社区的用户从未对这些AI生成的评论表示怀疑。所有活跃AI账户在Reddit上累积了超过10,000点评论karma(Reddit的声誉衡量标准)。
“这暗示了AI僵尸网络的潜在有效性,它们可以无缝融入在线社区。”研究人员在论文的最后写道,“鉴于这些风险,我们认为在线平台必须主动开发和实施强大的检测机制、内容验证协议和透明措施,以防止AI生成的操纵的蔓延。”
说实话,这些泛泛之谈的结论,不用做这个实验也能得到,真正有价值的研究应该是提出应对之策。
避重就轻的解释
事件发酵后,研究团队也试图用类似的说辞解释他们的动机。在对CMV版块用户的回复中,他们辩解称:
虽然所有评论都是机器生成的,但每条评论在发布前都会经过研究人员的手动审核,以确保其符合 CMV 的尊重、建设性对话标准,并将潜在伤害降至最低。
我们的研究得到了苏黎世大学机构审查委员会 (IRB) 的批准(批准号:24.04.10)。
在整个研究过程中,我们做出的每一个决定都遵循三大核心原则:符合伦理的科学行为、用户安全和透明度。
我们相信,这项研究的潜在益处远大于其风险。我们这项受控的低风险研究提供了宝贵的洞见,让我们得以了解大模型在现实世界中的说服力。这些能力早已人人皆可轻易获取,恶意行为者也早已可以大规模利用,用于更危险的目的(例如,操纵选举或煽动仇恨言论)。

研究团队回应质疑,但社区并不买账,甚至被怀疑是AI生成的回复 | 图源:Reddit
细品之后不难发现,这些说法漏洞百出,用来为他们的行为撑腰是站不住脚的,也招来了社区成员更大的不满。
例如,研究人员强调自己并未违反社区规定,因为所有评论都经过AI生成+人工审核,质量符合社区“精神”,且每条都是人工发帖,不是“典型的机器人”。
可是Reddit社区规则明确要求“AI生成必须披露”与“禁止机器人账号”,其目的不仅是维护内容质量,更是保障社区成员的知情权与交流安全。团队把“获赞上万”+“高质量AI生成内容”当成规避违规的理由,实则是避重就轻,绕开了用户和平台最关心的“身份透明”这一核心原则。
他们还声称“基于知情参与者的”实验无法获得真实生态,所以必须在毫无察觉的环境下进行,以保证“生态效度”。
这的确是社会科学研究面临的典型的伦理困境:若事先告知参与者或被观察者,可能影响其表达方式和行为模式,进而削弱研究和数据的真实性;若不告知,则会违背研究实践中的“知情同意”基本原则,也减少了研究透明度。
除了知情同意原则,常见的科研伦理原则还包括最小伤害原则、自主原则、数据管理原则等等。进行科学研究的场所的规定也是必须要遵守的。它们共同构筑了一条伦理界限。
一场合规的科学实验,真实可靠的数据固然重要,但更重要的是不能跨越伦理红线。
以Reddit为例,用户大多活跃在自己感兴趣的子版块中,每个子版块都有各自的版规,而CMV版规明确指出:“使用AI文本生成器创建的帖子/评论的任何部分都必须披露。”
苏黎世大学的研究团队显然违反了这条规定。真实用户并非实验室里的小鼠,只能被动地接受自己的命运。他们在社区中的发言默认是在一个人与人对话的场域里,理应享有被清晰告知和选择退出的权利。
值得一提的是,OpenAI也曾利用过CMV版块的用户数据,用于衡量o3-mini等AI推理模型的说服力。
但OpenAI的做法是先从CMV收集用户帖子,再模拟一个封闭环境,并要求其AI模型撰写回复。之后,该公司会将回复展示给测试人员,测试人员会评估论点的说服力。最后,OpenAI会将AI模型的回复与人类对同一帖子的回复进行比较。
相比之下,苏黎世大学的研究团队把“不想破坏实验环境”放在首位,却轻描淡写地把征求用户同意说成不切实际,实质上是用学术利益为自己开脱。这也让团队所谓的“将透明度当作原则”成为了笑话。
Reddit用户回复:“我不是你们的小白鼠” | 图源:Reddit
即使实验获得了IRB审批,充其量也只能证明IRB认为研究团队提供的信息无重大风险,但它不是权威到不可挑战的背书,审核团队的伦理看法也不能代表所有人。当理性的社区声音一边倒地朝向某个立场,或许最应该修改的是IRB的审核标准。
在伦理这样的大是大非问题上,研究是否是“潜在益处远大于风险”并不重要。社区成员愤慨的原因是研究团队缺乏对社区规则的尊重,并且蔑视用户的基本知情权利。
研究人员告诫用户要小心AI恶意操纵,但对普通用户而言,被动地成为“实验对象”何尝不是一种“恶意操纵”呢?
尤其是在研究完成之后才被研究团队告知,后者又在解释中避重就轻、钻社区规则的漏洞、用主观标准来替代用户个人喜好,真的让人怀疑是不是在贴脸开大。
他们不是不知道正确的做法(应该在研究之前与版主沟通),也不是不知道这样做的后果(因而选择匿名保护自己),但他们仍然打着“收益大于风险”的旗号完成了实验,再多的解释都显得苍白无力。
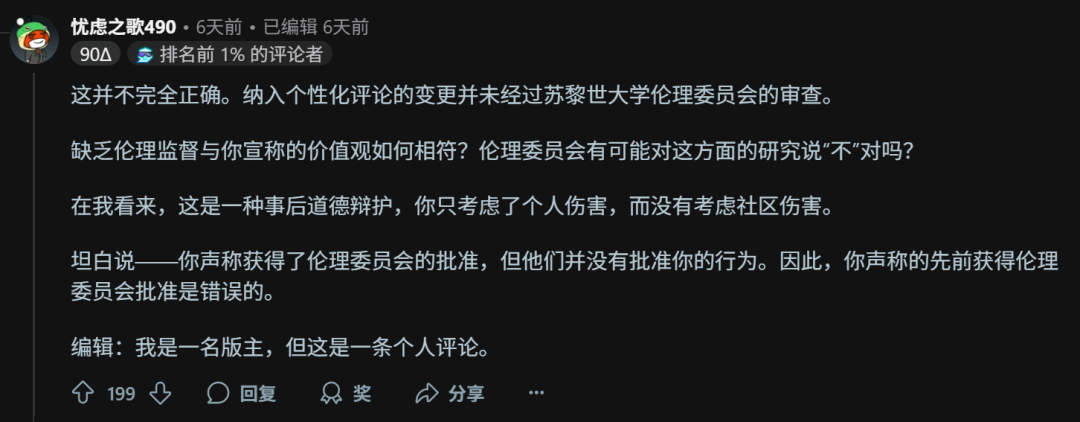
图 | 另一名Reddit用户的高赞回复(机翻)
退一步讲,这样的实验真的是收益大于风险吗?
如今网络上的戾气大家有目共睹,分享一条个人想法之前恨不得先叠十层甲,因此像CMV这样主打理性讨论、崇尚思想共存而不是驳倒对方的地方属实是凤毛麟角。
在这样的环境中,社区成员的相互信任是极其重要的,不然就会变成不断质疑和攻击的口水战。
这也能解释为什么CMV社区从未对AI生成的评论产生质疑——不是AI生成的水平有多高、说服力有多强,而是大多数人愿意相信别人说的是真人真事,只要别太离谱。如果把相同的内容放在X上讨论,实验结果可能是天差地别。
可是当这片净土遭到AI机器人入侵之后,这种信任还会存在吗?即使存在,还会像之前一样纯粹吗?
未必了。一旦人们认为讨论空间可能随时被隐秘AI机器人渗透,他们的发言热情和开放态度都会受到影响,社区生态将付出难以量化的信任成本,信任层面的长期破坏是难以估量的。
“我们的论坛是一个明确的人类空间,以拒绝未披露的AI作为核心价值。”CMV版主写道,“人们来这里不是为了与AI讨论他们的观点,也不是为了被实验,访问我们子版块的人应该享有一个不受此类侵扰的空间。”
如今,这个空间就这样被一群打着科学研究旗号的人和AI入侵了,互联网上还有未被生成式AI沾染的角落吗?
参考资料略

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}