2025年以来,全球内存市场出现了明显的涨价潮,部分产品价格甚至飙升数倍。市场研究机构 TrendForce 在2026年2月发布报告称:2026年第一季度传统DRAM合约价格预计环比上涨约90%–95%;与此同时,内存巨头三星和SK海力士也已通知部分客户上调DRAM报价,并可能在第二季度继续提高。为何看似“不起眼”的电脑配件内存会突然暴涨?这背后既有AI时代算力需求激增带来的瓶颈,也与业界产能向新一代高端内存转移相关。本文将从内存发展历史的角度,简要介绍这一支撑数字时代舞台的重要组件。
撰文 | 陈清扬
2025 年底开始,存储器尤其是内存迎来一波暴涨,这个并不太被大众关注的硬件组件,忽然走上了风口浪尖,甚至被戏称为 “理财产品”。在计算机算力蓬勃发展的时代,CPU和近年来崛起的GPU自然是众星捧月的焦点,以至于在人们的印象中,谈论算力便是谈论各代引领风骚的旗舰处理器。英特尔、AMD、英伟达等企业乘风破浪,站在了浪潮之巅。而内存,尽管始终在持续迭代,却似乎总是个不起眼的角色。
内存真的只是配角吗?事实上,当芯片世界讲述“摩尔定律”的故事时,它本质上在同步演绎着两条平行且紧密耦合的演化路线:没有强大的处理器,软件生态无法繁荣;缺少足够强悍的存储器,即便处理器的峰值算力再耀眼,也难以真正发挥价值。
让我们从半导体工业的历史说起。
一
1950~1970:从晶体管到 DRAM 的奠基
1955 年,晶体管的发明者之一威廉・肖克利(William Shockley)离开贝尔实验室,回到故乡加州山景城创办了肖克利半导体实验室。肖克利在科学界久负盛名,还获得了诺贝尔物理学奖,但其管理风格却是相当专横。不久,才华横溢的“叛逆八人组”便集体出走,创办了仙童半导体,就此掀开了硅谷与现代半导体工业的篇章。
晶体管这一基础元件,在随后几十年里发展出两条深刻影响计算世界的技术路线:一条是以逻辑运算为核心的处理器路线,另一条则是以信息存储为核心的存储器路线。事实上,晶体管诞生后,工程师们很快发现:这些“电子开关”既可以组成逻辑门,构建复杂的算术与控制电路;也能配置成保持状态的结构,用于记忆电荷、存储信息。因此,“逻辑”与“存储”最初并未分家,更像是半导体技术向两个不同方向的自然延伸。

图1 叛逆八人组。其中左一的戈登·摩尔(Gordon Moore)和左四的罗伯特·诺伊斯(Robert Noyce)再次出走创办了英特尔。图源:wiki
这两条路线在 1960-1970 年代逐渐成型,直接塑造了后续的科技格局。例如,英特尔创立之初并非以处理器闻名,而是瞄准了半导体存储器市场;与此同时,IBM 工程师罗伯特・登纳德(Robert Dennard)于 1966 年提出了 DRAM(Dynamic Random-Access Memory)的构想——以 “一个晶体管+一个电容”的极简结构实现可扩展的高密度存储,这一发明奠定了现代内存技术的基础。不过,登纳德的构想在当时过于超前,起初并未被 IBM 重视。
1970 年,成立不久的英特尔捷足先登,推出首款商业量产的 DRAM 内存 1103,容量仅 1Kb,它的发布震惊了世界——直接证明半导体内存可以成为计算机主存的未来,也宣告了传统磁芯存储器将退出历史舞台。与传统磁芯存储器相比,以 1103 为代表的 DRAM 内存体积更小、量产成本更低,问世后迅速被主流计算机采用,两年后便成为全球最畅销的半导体芯片。1971 年英特尔又推出了处理器芯片 4004——这是英特尔首款商业 CPU,也是全球首款采用集成电路的商业化微处理器。其时钟频率为 740kHz,制程工艺为 10 微米,每秒可运算 9 万次,尺寸仅指甲盖大小,性能却堪比 1946 年占地 167 平方米的世界首台通用计算机 ENIAC。相比之下,同一时期的 DRAM 内存 1103 的访问速度也处于相近量级。对于 CPU 的访问请求,它需要约 300~500 纳秒的“内部操作时间”来完成一次读取,即所谓的“访问延迟(access latency)”。在当时的系统中,这一速度足以满足处理器的访问需求。

图2 Intel 推出的首款商业化DRAM 1103,由3个晶体管和一个电容构成,以其体积和价格优势终结了传统磁芯存储器,并开创了DRAM作为主内存的时代。图源:wiki
二
1970~1990:内存与 CPU 的同步崛起
随着制造工艺的进步,晶体管尺寸不断缩小,集成电路上的晶体管密度持续提升,CPU 性能也随之进入近似指数级增长阶段。1965 年,英特尔创始人戈登・摩尔根据行业观察提出一个“定律”,即大名鼎鼎的摩尔定律:在价格不变的情况下,集成电路上的晶体管密度每年会翻一倍(1975 年修正为每两年翻一倍)。这并非物理定律,而是基于技术演进与经济学规律的判断,这一深刻的判断在之后几十年里成为半导体行业最有力的发展指引。每当技术瓶颈导致芯片发展放缓时,总能有新的革新出现,让摩尔定律持续生效。
1978 年,英特尔推出经典的 8086 处理器,频率达 5 MHz,相比此前的4004 处理器频率翻了7倍,集成的晶体管的数量更是翻了13倍。同时,DRAM 内存的容量也在随摩尔定律指数增长,同期的内存容量达到16Kb,为 1971 年的16倍。然而,内存读取速度的提升幅度已经开始落后于其容量和处理器性能的增长。不过在当时,这种差距尚未对整体系统性能产生明显限制,内存仍然能够基本跟上计算需求。
在 1984 年 1 月 22 日的美国“超级碗”赛事中,苹果公司为他们新款的个人电脑 Macintosh 投放了电视广告。在那个个人电脑刚刚兴起的年代,Macintosh 展现了一种全新的人机交互方式,它提供了图形界面,即用户可以使用鼠标点击与电脑交互,而非必须在终端里敲入命令。这次广告营销取得了巨大的商业成功,Macintosh 以2495美元(折算成现在的人民币约5.4万元)的价格,在不到5个月的时间里售出7万台。初代 Macintosh 使用了频率为 7.8MHz 的 Motorola 68000 处理器,内存的容量为128KB,后来它被苹果公司重新命名为 Macintosh 128K。从技术上讲,当时的内存技术其实已经可以实现更大的内存容量,譬如此前发布的 Lisa个人电脑便配备了 1M 的内存,为什么初代 Macintosh 的内存容量仅有 128K 呢?这其中的历史我们以后有机会再讲。最后实际上发生的事情是,尽管能够跑得起图像界面,但由于内存容量的限制,Macintosh 128K 的实际使用体验相当卡顿,于是后续销量疲软,一年后苹果公司推出了内存扩容后的 Macintosh 512K。值得一说的是,内存的容量和读取速度是两个不同的指标,在 Macintosh 128K 和 512K 中,系统性能主要受限于内存容量而非内存速度。

图3 1984年乔布斯推出初代 Macintosh,屏幕上显示的是日本新版画名作《梳发女子》,以此展示其领先的位图显示能力。图源:wiki
此后 CPU 性能的持续高歌猛进,进入 1990 年代初期,尽管内存的带宽和容量仍在增长,但延迟的改进却相当缓慢。这与内存的结构特性密切相关:晶体管本身的开关速度会随工艺改进而提升,CPU 完全由晶体管构成,因此能同步提速;但 DRAM 内存除晶体管外还包含电容,一次完整的内存访问需要经历预充电、感应放大、地址解码等过程,受限于电容物理充放电的固有特性,内存延迟难以持续降低。也是在这个年代,缓存——一种直接放置在CPU内部的高速存储——开始成为CPU设计的标配,直到现在。当CPU对内存进行数据读写时,常用的数据会被保存在缓存中,以便下次快速访问。相比 DRAM,缓存使用一种称为 SRAM(Static Random-Access Memory)的技术,SRAM 完全由6个晶体管构成,读写速度比DRAM更快,但是造价也更高,而且因缓存在CPU芯片内,其容量也远小于作为主内存的 DRAM。
然而,尽管有缓存这一方案作为对内存速度瓶颈的缓解,一部分学者和业界人士依然表示不乐观,他们预测,若内存速度与 CPU 的差距持续扩大,10 年后整个计算机系统的性能将完全受制于内存,CPU 再快也只能空等内存数据。由此“内存墙”(Memory Wall)的概念应运而生——就像高速高转的CPU撞上一堵墙。
三
1990~2010:内存墙的缓解与转化
1995 年,弗吉尼亚大学的两位教授在论文Hitting the Memory Wall: Implications of the Obvious中首次明确提出“内存墙”概念,此后该词汇逐渐在行业内流行。论文指出,由于 CPU 性能提升速度指数级高于内存,再过 10~20 年,即便 CPU 缓存实现完美命中,仅“强制性缺失(Compulsory Miss)”,即数据至少需要从内存被加载到缓存中一次,就足以让整个计算机系统的瓶颈集中在内存上。
如今 30 年过去,在个人电脑领域,这一预测显然并未成真——内存并非当前 PC 性能的主要瓶颈,随着 CPU 迭代,电脑整体性能仍在持续提升。背后有若干原因:
首先,1995 年的论文存在一个假设偏差:作者认为未来应用会访问越来越多的内存数据,导致 CPU 缓存无法容纳。但 CPU 的发展远超预期,如今个人电脑的 L3 缓存容量普遍达到了 16MB,巨大的缓存使得浏览网页、办公等常见应用的绝大部分内存访问请求都能直接调用缓存数据,无需触发真正的内存访问。
其次,CPU 架构取得长足进步,现代 CPU 十分擅长掩盖内存访问延迟——即便缓存未命中,CPU 也能智能执行后续独立指令,无需原地等待。如今的 CPU 乱序执行深度极高,以 2020 年底发布的苹果 M1 处理器为例,其集成了 160 亿个晶体管,乱序执行窗口高达 600 以上,意味着若某条指令需要等待内存数据,CPU 可提前查看后续 600 条指令,并行执行无需依赖该数据的任务。此外,现代 CPU 的 “数据预取(Prefetch)” 技术愈发智能,能精准预判后续需访问的数据并提前载入缓存。这些技术革新,使得内存延迟停滞的问题并未成为个人电脑系统的性能瓶颈。
此外,还有很重要的一点是在2006年左右,受限于物理限制,CPU的频率不再能继续提升,单核性能提升的脚步也开始放缓。也就是说,CPU自己也开始慢下了前进的脚步。

图4 2011年发布的高端桌面处理器 Intel Core i7-3960X processor die 示意图,16M的L3缓存占据巨大的面积。图源:silentpcreview.com
另一方面,虽然内存访问延迟长期改进缓慢,但内存带宽却在持续提升。1990 年代初,DDR(Double Data Rate)技术问世,通过在时钟信号的上升沿和下降沿均传输数据,内存带宽得到了大幅提升。这一趋势延续至今:DDR3 的最大带宽可达17 GB/s,2020 年发布的 DDR5 则将峰值带宽提升至51 GB/s。
那么,1995 年关于内存墙的预测是否完全错误?其实也不尽然,这与应用场景密切相关。前面提到的 CPU 缓存、乱序执行、数据预取等技术,足以应对网页浏览、办公、聊天等日常场景,在这些应用中内存带宽提升的感知并不明显。但在大规模数据分析、复杂模拟、高性能计算等对数据传输速度要求极高的场景中,内存带宽的提升能显著增强系统处理能力;即便CPU缓存再大也无法容纳全部所需数据,乱序执行的优势也会大打折扣。这类应用对内存带宽的需求极高,如今的 AI 应用恰恰属于这一范畴。因此,进入2010年代后,内存墙以“带宽瓶颈”的新形式重新出现——大量 AI 与高性能计算应用需要持续从内存中读取海量数据,使得系统性能越来越依赖内存带宽。
四
2010 年至今:AI 时代的带宽内存墙与突破
2012 年,AlexNet 在 ImageNet 图像识别比赛中夺得冠军,深度学习技术由此迎来爆发式增长。与传统机器学习相比,深度学习的数据处理量更大、计算量更庞大,但逻辑相对简单,这使得 CPU 的技术优势几乎无从发挥。相反,此前主要用于图形计算的GPU,找到了理想的新应用场景——图形计算的核心是对海量像素点进行独立重复计算,数据量大、并行度高,与深度学习的计算模式高度契合。
然而,深度学习的计算量极其庞大,即便 DDR5 内存的带宽也难以满足需求。人们常关注 GPU 的海量计算单元,但在 AI 场景中,内存带宽才是真正的性能瓶颈。高性能计算领域经典的 Roofline 模型,直观展示了软件算术强度、硬件计算能力与内存带宽的关系:在 AI 计算中,相当一部分应用的算术强度较低,整体性能往往受限于 GPU 的内存带宽。由此,带宽成为 AI 时代的新“内存墙”。
就像摩尔定律多次在终结边缘被工程师创新延续一样,带宽内存墙也迎来了解决方案 ——3D 堆叠内存技术。工程师们将内存以 3D 堆叠形式直接集成在 GPU 或 CPU 附近,而非像传统 DDR5 那样通过主板内存通道连接。3D 堆叠结构与物理近距离布置,让内存能提供极高带宽:例如 HBM(High Bandwidth Memory,高带宽内存)采用 1024 位总线,而传统 DDR5 仅为 64 位总线,带宽可达 DDR5 的数十倍。
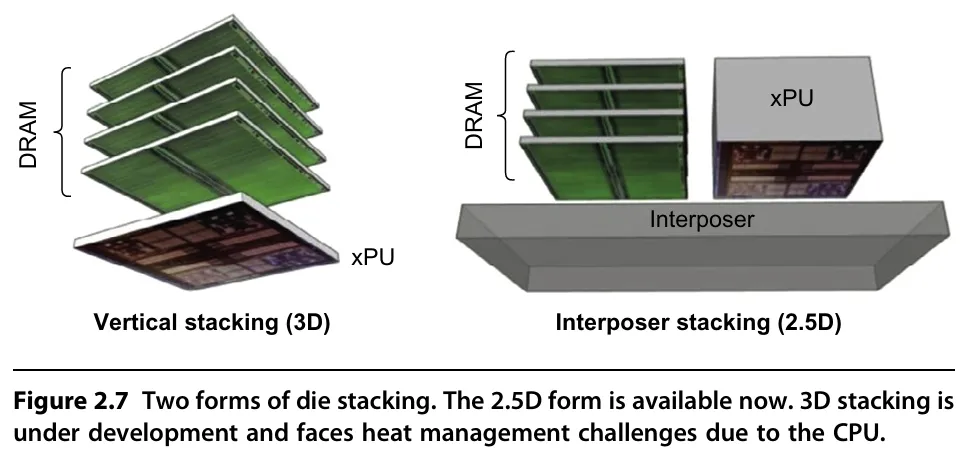
图5 使用3D堆叠技术的HBM内存,图源:Computer Architecture: A Quantitative Approach7th edition
在 HBM 技术加持下,GPU 的 Roofline 模型“斜屋顶”被显著拉高,AI 计算性能大幅提升,带宽内存墙得以有效缓解。但需注意的是,HBM 的发展已不再严格遵循摩尔定律——原始摩尔定律的核心前提是成本可控, HBM 虽带宽极高,但价格十分昂贵,且成本提升伴随带宽同步增加。以英伟达的 H100 GPU为例,其 HBM3 内存的成本已占总制造成本的一半,这一比例在后代的 GPU 中可能继续上升。此外,HBM的容量通常要比DDR内存小许多,这是因为散热以及制程物理上限制了其3D堆叠的最大层数,以至于容量难以扩展太大。
如今各大 AI 公司纷纷加码算力中心建设,对 HBM 的需求激增。内存厂商为追求更高利润,开始将产能向 HBM 倾斜——一片晶圆制造 HBM 的利润可达 DDR5 的三倍,这导致传统内存产能大幅收缩,市场供不应求,进一步推动了 2025 年底以来的内存价格上涨。从产业界角度来看,内存市场的供需失衡并非个案,而叠加内存生产的特殊性,进一步加剧了价格波动:内存生产线投资巨大、建设周期长,扩产难度极高,往往需要数年时间和数百亿资金投入才能形成有效产能。值得注意的是,过去行业内曾多次发生工厂事故影响产能,比如SK海力士无锡工厂曾因火灾导致DRAM生产线全面中断,直接推动存储芯片价格暴涨19%,这类突发情况进一步放大了市场供需的不确定性。
与此同时,全球内存产业的技术竞争愈发激烈,中国近年来在内存领域持续发力,成为全球市场的重要变量。国产 DRAM 厂商长鑫存储自 2016 年成立以来,经过多年研发投入,已逐步建立起完整的 DRAM 研发和制造体系。近年来公司相继推出 DDR4、DDR5 以及 LPDDR5X 等产品并进入量产阶段,随着行业周期回暖和新产品放量,公司的经营状况也在持续改善。与三星、SK 海力士、美光等国际巨头相比,长鑫在先进制程和 HBM 等高端产品上仍存在差距,但在主流 DRAM 产品领域正逐步靠拢。一些国内厂商和云服务企业也开始尝试采用其产品,国产存储产业链的能力正在逐步提升,成为传统三大厂之外全球内存市场新的竞争力量。
五
未来:容量成为新的内存挑战
AI 发展迈入大模型时代,工程师们刚刚突破带宽内存墙,却又显得“落后”了。大模型不仅需要处理海量数据、对带宽要求极高,模型本身的参数规模也极为庞大,这使 HBM 的容量逐渐成为新的限制因素。如何在有限的内存中存放海量模型权重,成为行业面临的新挑战。当内存硬件工程师寻求技术突破时,算法与软件工程师也在通过优化模型架构、降低精度、设计高效计算策略减少内存占用,实现大模型在有限内存下的高效运行。
从 1950 年代的晶体管诞生,到 1970 年代 DRAM 技术奠基,再到今天 AI 时代对内存带宽与容量的极致需求,内存的发展始终与计算能力的提升紧密绑定。尽管内存从未像 CPU 那样万众瞩目,但正是它在背后默默支撑,让现代计算机的算力得以充分释放。此次内存涨价,不仅是市场供需关系的体现,更提醒我们:在计算机世界里,没有真正的配角,每个组件都在支撑着数字时代的庞大舞台。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}