对于大部分的实验科学,搭建设备和采集数据是工作的重点,高能物理领域也是如此。随着高能实验进入大科学工程时代,数据日渐庞大、分析技术飞速发展,采集数据之后的工作逐渐变得重要和复杂,实验物理学家的身份也因此迅速变化。
撰文 | 肖朦(浙江大学物理学院)
作为一名在大型强子对撞机(LHC)工作的高能物理实验学家,惭愧地说,我从未动手建造过其中的任何部件,甚至直到我在LHC工作的第五年,名下已有好几篇关于LHC的学术文章,我才见到了探测器本尊。所以当别人问起我是做什么的时候,我总感到万分艰辛:
“听说你们实验花了很多钱?”
“确实,建造大概花了50亿瑞士法郎。”
“这么大工程啊!那你是设计实验还是操作仪器的?”
“都不是,我们有非常专业的同事来完成这些事情。”
“那你干什么呢?”
“我主要分析数据。”
空气通常在这时就凝固了。竟有实验物理学家不做实验,依靠别人给的数据生存。分析数据不就是整理结果嘛,还需要专门设置一个职业,而且还需要博士文凭?
这倒不是什么离谱的刻板印象,1960年到1980年的粒子物理实验就常常雇佣一些临时员工来分析数据。那时一般用气泡室作为探测设备,带电的粒子经过它们时会电离,产生肉眼可见的“径迹”,每隔几秒就会有一张照片记录这些径迹,物理学家就利用这些照片来寻找新的粒子或新的物理现象。(编者注:参见《自己动手,在家做一回粒子物理实验》)
和这个世界的大多数事情一样,经常发生的没意思,有意思的不经常发生。物理学家需要在一张张照片中寻找这些反常的事件,这就是所谓的分析数据,是一项工作量很大的工作。于是他们雇佣大量的临时科研人员甄别这些照片,将反常的照片挑出来供物理学家进一步分析。这听上去确实很枯燥,而且这些付出了大量时间的人,甚至不会在最终的文章中留下名字。(因为大部分被雇佣的临时科研人员都是女性,历史上有人称她们为“Scanning girls”,如果你对她们和这段历史感兴趣,可以读读这篇报道。)
那现在情形如何呢?当然是发生了很大的变化。这个变化可不是临时工被替换成了收入同样微薄的博士生,并允许他们在文章中出现名字这么简单。粒子物理实验进入大科学工程时代后,数据量突飞猛进,远远超过人工所及。在LHC上,质子束以每秒4×107的频率迎头碰撞,并被轨道上四个主要的大探测器记录下来。LHC是目前世界上最大的随机数产生子,如果有人不相信量子力学,一定要让他来看LHC的数据。你永远都不知道下一次碰撞出的到底是两个胶子,还是一对正反顶夸克。但是理论计算告诉你后者的概率要小得多,如果你把采集到的数据逐个翻一遍,你会发现产生正反顶夸克的个数确实和理论预言的一样。
这时新的挑战来了:由于传输和存储的限制,保存所有数据是不现实的,因此要进行快速筛选。要多快呢?为了避免不断碰撞出的数据挤爆缓存和存储设备,我们需要在0.000001秒内,从400个数据中粗选出1个有用的数据,再在0.1秒内从100个这样的数据里挑1个存储。这个被称作“触发”的过程扔掉了大部分的实验数据,而保留的事件由我们关心的物理决定。
筛选条件需要根据物理进行调整:比如我们想从数据中找到Z玻色子(传递弱相互作用的中性粒子),于是触发会要求事件中含有两个高动量的电子或缪子,因为他们是Z玻色子常见的衰变产物;或者我们想寻找一个标准模型没有预测的新粒子,它会表现为一个包裹着两个底夸克的高动量喷注,于是触发既要寻找到一个喷注,还得鉴别它内部的信号真的来自于底夸克。显然,我们需要机器来完成触发,但告诉机器怎么做可不是一件容易的事情。在LHC上,对撞产物留下的信息千奇百怪,光是带电径迹就有上千条,还有散落在各处的能量沉积,一切乱糟糟的,你很难一眼看出哪里有电子,更不要说鉴别它们的种类了。
这一切迫使粒子物理实验学家成为机器学习和图像识别的高手。早在1990年,欧洲核子中心LEP实验的粒子物理学家就已经将神经网络运用在了触发系统上;在现在的LHC上,我们也是利用重建和鉴别算法将探测器中复杂的信号识别为不同类别的粒子,再进而完成触发的。
听过LHC的人大概也听说过希格斯玻色子,它的发现是LHC目前最著名的成果,由此验证了1964年提出的希格斯机制,完成了标准模型的最后一块拼图。事实上在LHC上搜寻希格斯玻色子,于2010年正式取数开始,2012年物理学家就宣布了这个重要结果。这么看来,在经过进行复杂的触发系统筛选后,实验学家们似乎轻松愉快地就找到了希格斯玻色子。但我以当年在欧洲核子中心看到的无数熊猫眼向你保证,这个过程可没有那么简单。
以LHC上的探测器CMS为例,每秒CMS都会存储几个Gb的数据,一年运行下来,累积存储了十几个Pb。借用LHC的官方宣传,这些数据相当于1千万张DVD,如果把它们堆起来,将会有12千米高。在这海量的数据中,实验学家们最后发现了多少希格斯玻色子呢?下面这张图片来自于当年的发布会,你用几秒就能数出“黄金道”四轻子末态中的数据个数,能被称作疑似希格斯玻色子的事件大概只有14个,其中一半还是偷偷混进来的“背景”——就是那些并非希格斯玻色子,但却被选中的事件。
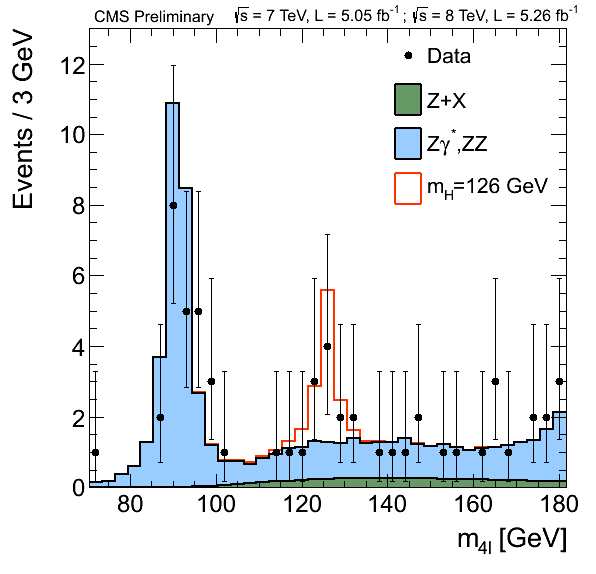
希格斯玻色子的产生截面(即概率)很小,是LHC物理总截面的10-10倍。想要在这茫茫数据中找到这些稀有的希格斯玻色子,我们需要对它进行非常精准的特征刻画,量身定做选择条件,最终筛选想要的结果。打开任意一篇LHC的文章,你会发现实验学家们在这方面下了很大的力气,用各种方法去除或区分背景。机器学习大概是其中最常用的工具了。然而无论这些方法多么复杂、多么细致,筛选出的事件总会混入一些背景,这时物理学家会陷入两难境地:放宽条件会混入更多背景,而下狠手严格筛选的话,可能连我们想要的数据——也就是信号——就会不剩几个了。
于是实验学家们还得精通统计学,将最终得到的数据翻译成一个叫显著度的东西,由此衡量结果的好坏。你大概很难想象,LHC上的实验学家们常常需要花上少则一年,上无封顶的时间来确保所有的随机涨落和系统误差的正确性,因为不严谨的误差处理对显著度有巨大的影响。误差的大小取什么值合适,应该如何关联,以及它们应该符合对数正态分布、还是平均分布,这些都需要仔细推敲。实验学家们还发明了很多验证统计结果可靠性的测试,如果你路过一间办公室,听到有人在咆哮道:“JES(喷注能量标度)怎么又被over constrained了?!”不要惊讶,这只是一个粒子物理实验室的博士生在进行日常的系统误差检查。
当然,显著度只是诸多统计表达中的一种,我们关心的物理问题不同,统计方法和表达方式也会发生变化。现代粒子物理数据分析就是一个将海量数据转换为一个简单的数字或结论的过程,实现这个过程需要庞大的知识体系,包括粒子物理理论、探测器技术、概率论和数理统计知识、数据处理机器学习和强大的编程能力。博士生们常常开玩笑,说他们一半的时间在写代码,一半的时间在找bug,但要设计代码并理解程序运行的结果,靠的还是全面的物理和统计知识。有人提议将粒子物理实验学家改名为“数据物理学家”,我觉得这倒贴切地反映了这个行业所需要的技能。
如今,在粒子物理中,物理学、数学和计算机科学的交叉融合正在慢慢改变分析方法。得益于深度学习的发展和应用,从探测器的信号中鉴别粒子种类的能力在过去几年飞速发展,传统的逐个事件筛选方法被新的方法代替,速度可以提升100倍。这些方法很多是由年轻人提出并实现的,他们知识的全面性常常超过了我的预期。我想我们的本科和研究生教育也需要提供更多的课程和实践以适应学科的发展,让他们有更坚实的基础去创新。
在为这篇稿子做调研时我读到一则新闻,三名MIT的博士生基于他们处理LHC大量数据的经验,成立了一家云数据库服务公司Cloudant,这家公司在2014年被IBM收购。我希望在不久的将来,我们的博士生也可以用他们的专业知识来改变世界。
有人说粒子物理的终极模型也许会由大数据模型给出,尽管我对这个惊人的理论感到难以消化,但谁知道呢,让年轻人来告诉我们答案吧!
本文受科普中国·星空计划项目扶持
出品:中国科协科普部
监制:中国科学技术出版社有限公司、北京中科星河文化传媒有限公司

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}