2024 年 4 月 8 日辛顿获得尤利西斯奖章,以表彰他对计算机科学人工智能领域的贡献。他通过在计算和工程两方面的突破,使得深度神经网络成为计算的关键组成部分。本文为杰弗里·辛顿在获得尤利西斯奖章时发表的演讲,简明扼要地介绍了神经网络和大语言模型的基本概念和工作方式。
尤利西斯奖章是都柏林大学学院颁发的最高荣誉。该奖项设立于 2005 年,以校友、爱尔兰作家詹姆斯·乔伊斯(James Joyce)的著作《尤利西斯》(Ulysses )命名,授予为全球做出某种杰出贡献的个人。
演讲 | 杰弗里·辛顿
翻译 | 陈国华(北京外国语大学外国语言研究所教授)

“人工智能教父”杰弗里·辛顿荣获都柏林大学最高荣誉尤利西斯奖章。丨图片来源:Chris Bellew/Fennell Photography
非常感谢学院赞誉有加的颁奖辞[1]。
我想特别指出一点,那就是,我的成功在很大程度上归功于能够招到真正优秀的研究生。因此我们永远不要忘记,在这一领域,工作是研究生做的。
只要有机会给他人讲课,我就无法拒绝。很多人实际上并不知道人工智能是怎么回事。因此,我将用大约20分钟做一个非常基础的、关于人工智能如何工作的演讲,让那些不喜欢方程式、不知道这些大型聊天机器人究竟在做什么或如何做事的人们,知道是怎么回事,还请计算机科学专业的学生和已经知道人工智能是怎么回事的各位海涵。
自上世纪中叶以来,对智能的研究一直存在两种范式。一种是受逻辑学启发的思路,其概念是智能的本质是推理,这是让人类如此特别的关键因素。推理是用符号规则操纵符号表达式来实现的,所以,我们真正要做的是了解知识是如何表征的,是用什么类型的逻辑编程语言来表征的。学习之类的事可以等到以后再做。
另一种是受生物学启发的思路,这一思路完全不同。这一思路认为智能的本质是学习,学习神经网络中连接的强度,逻辑和其他事情要晚得多。我们得先了解人是如何学会控制自己的身体或识别物体之类的事情,推理之类的事之后再说。
什么是神经网络?我给大家看一张神经网络示意图。
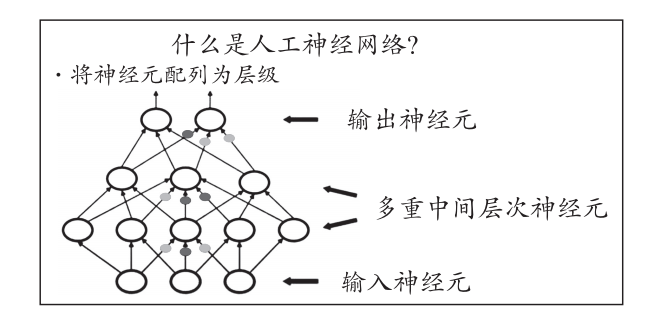
图1:人工神经网络输入-输出层级关系示意图[2]
底层是一些输入神经元,即一幅图像各个像素的强度值[3]。然后是多重中间层神经元,这些神经元会学习从图像(即输入数据)中提取特征。然后是上层的输出神经元,这些神经元可能会说出这是一张什么物体的图像。例如,输入的可能是一张猫图或狗图。你想要神经网络做到的是,给它输入一张猫图,代表猫的神经元就会在输出端亮起(即输出结果是“猫”)。连接线上的那些小彩色点是连接强度(译者注:原图红色小点用黑色表示,绿色小点用灰色表示)[4]。神经网络所要做到的是学会这些强度参数,以便输出正确结果。
有一种简单的神经网络学习的方法,每个人都能理解。
我们从一些随机连接强度开始。选取其中一个连接,稍微改变一下它的强度,比如稍微增强一点,看看输出的结果是否有改进。要判断输出是否有改进,我们得通过神经网络运行相当多的例子,看它能否给出更好的答案。所以,一开始可能它会说,这张猫图是“猫”的概率是50%。我们改变这个权重后,它可能会说是51%,这就是有进步。我们就这样修正权重,然后选取另一权重来试,然后继续这样做。如果做的时间足够长,我们会得到这样一个神经网络——当你把猫的图像展示给它时,它会说这很可能是“猫”;当你把狗的图像展示给它时,它会说这是“狗”。但如此修正的速度非常非常慢,因为处理每个连接,神经网络得尝试许多例子,而且我们得多次更新每个连接。
后来我们发现可以用一种有效得多的办法来实现同一目标。这是一种被称为“反向传播”[5]的算法。首先,我们拍摄一个物体的图像,把它传输给神经网络,通过这个网络来识别。假设它说有50%的概率是“猫”,那它给出的就是个误差,因为我们希望它说这个图像100%是“猫”。于是我们通过这个网络发回一个信号,而且就是通过前面那个传达误差的神经连接发回去。大致而言,我们可以计算,而不是衡量,改变一个权重会怎样改善这个网络的输出。所以,对于每一权重,我们都可以弄清楚,如果稍微增加这一权重,结果会不会好一点?或者,如果稍微降低这一权重,结果会不会好一点?我们现在可以采用并行的方式对所有权重执行这一操作。如果有十亿个权重,并对这些权重采用并行运算,速度就会快十亿倍。这就是神经网络的工作方式。我们通过反向传播误差来改变每一权重的算法,只是某种相对简单的微积分。关键的一点是,它确实有效。神经网络可以通过这种方式学习识别事物。
多年来,计算机科学家、计算机视觉研究者们一直都希望实现这样一个目标:给机器输入一个图像,机器就输出一个标题,说明该图像的内容。但他们做不到,远远做不到。而现在神经网络能够做到这一点。我们用反向传播算法训练神经网络,让它学会从图像中提取一批多层级的特征,这些特征的确能让计算机识别出图像的内容。
2012年,Alex Krizhevsky和Ilya Sutskever,在我的一点点帮助下,开发出了一个比已有计算机视觉系统好得多的深度神经网络。
接着发生了一件在科学界非常罕见的事情。计算机视觉研究领域的权威专家原先一直说神经网络永远无法做到这一点,现在却说:“哇,它还真有效!”而且他们改变了之前的做法,开始使用神经网络。这可不是科学家通常有的行为方式,当然也不是语言学家通常有的行为方式。下面,我们就谈一谈语言问题。
符号人工智能圈的许多人说,层级特征检测器[6]永远无法用来处理语言,根本行不通。我的网页上就引用了这句话。我实在没忍住,于是就让GPT4来详细解释这句话错在哪里。所以现在的情形是,我们有GPT4,它能向语言学家解释他们说的为什么不对,说明神经网络能做什么,不能做什么。语言学家被一个叫乔姆斯基的人误导了好几代——此人实际上也获得了这枚享有盛名的奖章[笑]。可见,名望不会持久[笑]。他有一个偏执古怪的理论,即语言不是学会的。他成功地说服很多人相信这一点。这个说法显然是一派胡言。语言显然是学会的。大型神经网络学习语言,不需要任何先天结构,只是从随机权重和大量数据中开始学习。乔姆斯基却仍然在说,但这并非真正的语言,这不算数,这是不对的。许多统计学家和认知科学家也说,永远不可能在这样一个大网络里学习语言。乔姆斯基从来没有提出任何一种有关语义的理论, 他的理论全是关于句法的。
我们如果考虑语义,就会发现有两种截然不同的语义理论。一种是符号人工智能研究者相信的结构主义理论,大多数语言学家也相信这种理论,即一个词的意思来自于它与其他词的关系[7]。
你如果想捕捉一个词的意思,就需要制作一个关系图,图中包含这个词与其他词的链接,也许还有链接点上的标签,说明它怎样与其他词相关。这就是一个语义网络,是捕捉意思所需要的。
此外还有一种非常不同的理论,来自1930年代的心理学,即一个词的意思是一个大的特征集合,意思相近的词具有近似的特征集合[8]。
这两种理论看起来完全不同。但实际上,我们可以把二者统一起来。我认为第一个做到这一点的是我在1985年制作的一个小型语言模型。这个模型与现在的大语言模型有很多共同之处。它通过尝试预测下一个词来学习。具体而言,它学习每个词的特征以及这些特征之间的相互作用,这样就可以预测下一个词的特征。重要的是,所有知识都体现在给一个词分配哪些特征以及不同词的特征应该怎样相互作用。这个模型不存储任何句子,却可以重构句子,也就是通过反复预测下一个词来生成句子。这也是大语言模型的工作原理。它实际上不存储任何文本,而是学习从文本中提取特征,把它分配给各个单词,并提取这些特征之间的相互作用,这样就可以预测下一个词的特征。
这个微小的语言模型并非旨在为工程助力,而是旨在解释人们如何通过语言来表达和领悟意思,所以它实际上是人类语言的工作模型。如果有人告诉你这种模型不像我们,跟我们的工作方式完全不同。你就问他,那人类语言是怎样工作的?他如果是语言学家,会告诉你,“用符号规则,用操纵符号表达式的规则”。但实际上,那些说这种模型和我们人类不同的人,实际上并没有什么模型,来说明人类语言是怎样工作的,所以我也不知道他们怎么知道神经网络模型跟我们人类的模型不同。然而神经网络研究者却的确有一个我们人类语言如何工作的模型。下面我详细介绍一个小模型,因为我一直认为,理解一个小的具体事物比进行虚而不实的抽象要好得多。虚而不实的抽象看着了不起,但要真正理解事物, 需要一个细微的具体例子。
这里有两棵家谱树。
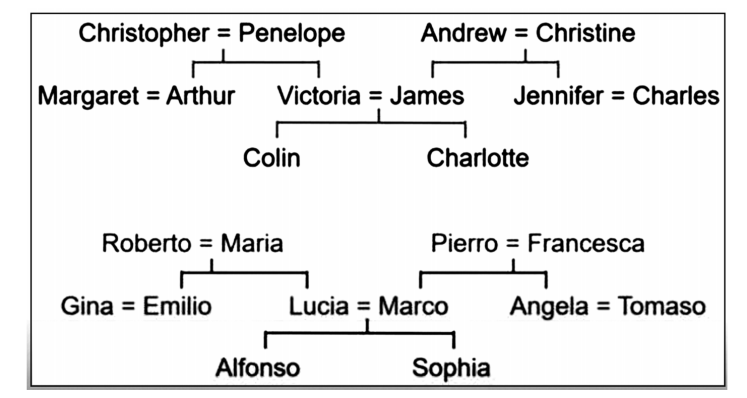 图2:家谱树示意图
图2:家谱树示意图
图中一些是英国人,还有一些是意大利人。这是1950年代,那时的家庭非常非常简单,没有离婚,没有收养,没有同性婚姻,都是很常规的家庭。你可能会注意到这些树有些类似,具有相同的结构。我们将把这些关系树变成一串三元组。从这些关系树中,我们可以通过一些关系术语(如儿子、女儿、侄子、侄女、母亲等)来记录信息。然后我们可以制作下面这样的三元组:
科林有父亲詹姆斯,科林有母亲维多利亚,詹姆斯有妻子维多利亚。从“科林有父亲詹姆斯”和“科林有母亲维多利亚”,我们可以推断出“詹姆斯有妻子维多利亚”。因此,研究符号人工智能的人认为人脑里有这些符号串的表征,同时,还有允许你从旧的符号串中得出新的符号串的规则,比如:
(如果X有母亲Y)且(Y有丈夫Z),那么(X有父亲Z)
这就是他们心目中逻辑的全部工作原理。
我所做的是制作一个神经网络,只要调节网络的权重,该网络就能学会上面那种知识。但该网络内部不储存符号串,不存储任何符号表达式,里面全是特征和特征之间的相互作用。在神经网络中做这件事,关键问题是,对于一清二楚的规则,你或许能够采用符号的方式来做。但我们的大部分知识并非完全正确,有很多例外。一旦出现了不符合规则的例外情况,使用大神经网络来找这些规则,效果会好得多。
我当时使用的神经网络看起来是这个样子。它底层有两个输入:一个是仅代表某人名字的单个(discrete)符号,另一个是表示关系名称的单个符号。我们想要的输出是一个人的名字,这个人与以上两个输入有着上述关系。训练用的数据就是这个样子。神经网络要学会的是先将一个人的名字转换成一串特征。就这些家谱树而言,这些特征代表这个人的本质。一旦神经网络为这个人和这一关系完成了这种转换,它就会让这些特征集合在中间相互作用,就可以预测输出人的特征,然后根据输出人的特征,就可以预测出输出人是谁。这种方法效果很好,可以让神经网络学习。它可以重新产生输入给它的事实,也就是说,如果所学的权重里信息足够多,你给它一个用于训练的例子,它就能给出正确答案;不仅如此,它还可以推断。也就是说,你可以给它输入它从未见过的例子、从未见过的人名、从未见过的关系、从未见过的组合,它也能给出正确答案。问题是,它是怎样做到这一点的?答案是,它学会了相当于我们心目中的自然特征的东西。拿人来说,神经网络学会了一个人的某些特征,比如国籍,例如,如果知道输入人是英格兰人,就知道答案是,国籍是英国;如果输入人是意大利人,那么输出答案就是,国籍是意大利。
我刚才说过,这两个家庭是非常简单的家庭。这也是个很小的网络,瓶颈层[9]中只有六个神经元,分别代表国籍、这个人属于哪一辈、属于家谱树的哪个分支;其中辈分特征会有三个值,因为有三辈人(最下辈、中间辈或最上辈)。这种辈分特征只有在学习关系特征时才有用。比如,这种关系要求输出人比输入人高一辈。比如“叔侄”关系就是这样。神经网络如果知道输入人的辈分,而且知道关系特征是高出一辈,就可以预测输出人的辈分,这有助于它输出正确的答案。这就是它的工作原理。而且它的确发现了符号人工智能研究者所相信的符号规则。这些研究者当中没有人抱怨这不是真正的学习。他们说,“好吧,它是在学习,但这是一种很笨的学习方式。”
再看大语言模型,它可以被视为(我个人认为)前面那个小模型的后代。他们对这个小模型做了调整,使之增大了许多,也复杂了许多。所以它有更多的词,适用于自然语言,而不仅是些简单的示例。它使用更多层级的神经元,因为不能从符号就直接得出意义。有的符号可能像may这个词,可以指一个月份,可以是一个情态词,也可以是一个女子的名字。我们得利用上下文来消除歧义,比如用层层向上推进的办法,所以神经网络有更多的层次。不同词的特征之间的相互作用也就要复杂得多,但它与小模型在本质上属于同一类模型。神经网络学习时,会将所有信息存储在特征之间交互作用的权重中。
语言学家说,这只是美化了的自动补全,只是在利用统计学的把戏,只是在将文本临摹拼凑在一起。但请记住,神经网络不存储任何文本。硬说它是自动补全而不承认它是学习,就是在胡言乱语,因为他们脑子里想的是一种老式自动补全。老式自动补全会存储词串,例如fish and chips这个常见的词串。如果你看到了fish and,你可能会说,下一个词很可能是chips,因为这是个非常常见的词串。而神经网络根本不是以这种自动补全的方式工作的。它将词转换为特征,并利用特征之间的交互作用来进行预测。
因此,大语言模型的工作方式,以及我们人类的工作方式就是,我们看到很多文本,或听到很多词串,进而获知词的特征,以及这些特征之间的交互作用。所谓理解,就是这么回事。神经网络模型正在以与人类完全相同的方式做理解。
语言学家的另一个论调是,这种模型是在制造幻觉,它实际上并不真的理解自己在说什么。就语言模型而言,这不应称为制造幻觉,而应称为“非故意虚构”(confabulation)。自1930年代以来,心理学一直在研究这个问题,人们惯于非故意虚构。这种模型进行非故意虚构这一事实,使之实际上更像我们人类。大多数人认为我们的记忆就像一种文件,你把它放在某处,然后去那里把它取回来,就像把信息输到电脑里然后把它读取出来。但人类记忆根本不是这样。人的记忆总是在重构。如果你回忆最近发生的事,你的重构会相当准确;如果回忆很久以前的事,你就经常会把所有细节弄错,而且根本意识不到这一点,反而会对这些细节信心十足。这方面的一个极好案例就是John Dean的记忆。
就水门事件,John Dean曾宣誓作证,回忆白宫各种会议上发生的事情,可是却把细节全弄错了。他说Haldeman说了什么什么,但实际上说这话的是另一个人,Haldeman根本没有参会。关于他的证词,毋庸置疑的是,他是在尽力说实话。他说出了事情的要点,即他们试图掩盖水门事件时究竟发生了什么。但他以为自己记得很清楚的细节,其实是错的,没有全错,但很多都记错了。Ulrich Neisser有一篇论文很好地证明了这一点。John Dean以为自己记得很清楚的事情,你一听录音带就知道他根本记错了,但他记住了事情的实质。
这是个极好的例子。
现在,聊天机器人在非故意虚构方面的表现比我们人类糟糕。它这种虚构的频率比我们高,而且不知道自己是在非故意虚构。但它一直在进步。我认为不久后,聊天机器人在非故意虚构方面不会比我们差多少。聊天机器人是在非故意虚构,这一事实并不表明它不理解自己做的事或与我们人类不同,反而表明它与我们人类非常相似。
我的演讲到此为止。我想对大家说的是,这些大型聊天机器人不像普通的计算机软件,反而更像我们人类。由此导致了一大堆人工智能的风险。这些风险我暂且不谈,有关内容可以参考这篇存档论文[10]。
好,我说完了。
注释
[1] 刘海涛使用录音笔和翻译软件完成演讲的英文转写和英汉翻译,提供了一个原始版本。在此基础上,译者根据现场录音,校勘英文转写并全面修订译文,后经编辑部审核定稿。英文转写文本经过辛顿审核,并许可演讲稿的翻译出版。熊文新、詹卫东、梁昊、李葆嘉、袁毓林都参加了译稿的润色。詹卫东对译文中涉及 AI 语言技术细节的表述提出了很多宝贵的专业意见。詹卫东和李葆嘉的一些解释有助于理解辛顿演讲的内容和背景,故此用作译文的脚注。
[2] 原图为幻灯文件页面,图题为编者所加。下文图 2 同。
[3] 即图像每个像素的亮度值和颜色值等。(詹卫东注)
[4] 即神经元之间的连接权重参数 。(同上)
[5] “反向传播”是backpropagation(简称BP)在人工智能界通行的中文译名,它指一种算法,即,在神经网络的训练中,所建模型从输入开始,先用前向传播,得到输出结果,然后比较输出结果跟期望结果之间的差距(误差),计算损失函数值,再从输出层开始,逐层向输入层方向(即向后)计算每个神经元的梯度,即损失函数值对每个参数(权重和偏置)的偏导数。利用链式法则,将梯度从输出层反向传播到输入层,逐层更新每个神经元突触的权重参数。BP算法是神经网络训练最核心的算法之一,能使神经网络高效地学习和调整参数,从而在训练数据上取得良好的性能。由于辛顿等人的工作,使得误差反向传播算法成为大规模多层(深度)神经网络参数(权重)学习的标准方法。(同上)
[6] 即深度神经网络。(同上)
[7] 此为现代语义学的第一块基石——德国学者创立的语义场理论。1924 年 G. Ipsen 受格式塔理论的影响提出语义场。1931 年 J. Trier 提出语义聚合场。1934 年 W. Porzig 提出语义组合场。1968 年M. Quillian提出语义网络。1973 年 R. Simmons 提出语义网络理论。1985 年 G. Miller 主持研制词网。(李葆嘉注)
[8] 此为现代语义学的第二块基石——美法学者创立的义征分析法。1937 年 K. Davis 提出亲属称谓的基元分析法。1956 年 W. Goodenough、F. Lounsbury 沿用此法。1963 年 J. Katz 和 J. Fodor 将语义成分分析法导入生成语法。1960 年代 B. Pottie、E. Coşeriu、A. Greimas 提出词的所指由语义要素组成,图像所指和语言所指相同。语义特征分析法可追溯到德谟克利特的原子论,以及笛卡尔、 A. Arnauld 和P. Nicol 的语义基元论。(同上)
[9] 该神经网络瓶颈层的特征数量显著少于前一层和后一层的特征数量。这一层通常用于降维或压缩信息,以提取最重要的特征。(詹卫东注)
[10] Yoshua Bengio 等,Managing extreme AI risks amid rapid progress, [2024 年 7 月 11 日最后访问]。
本文原载于《当代语言学》2024年第4期,原标题《杰弗里·辛顿接受尤利西斯奖章时发表的获奖感言》。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}