人工智能(AI)是否有能力研究理论物理?在本篇特邀文章中,物理学教授Matthew Schwartz 决定通过指导Claude(一个人工智能大语言模型)完成一项真正的科研计算(涵盖从起始到结束的全过程)以探究这个问题,在此期间他本人从未亲手编辑过任何文件。这项工作始于2025年12月最后两周,论文于今年1月上传至arXiv,随后引发了物理学界的广泛关注。以下是他对该探索过程的详细记录。
撰文 | Matthew Schwartz(哈佛大学物理学教授)
翻译 | 李磐
总结
我指导 Claude Opus 4.5 完成了一项真正的理论物理计算工作,通过文本提示词(prompt),将复杂的代码编写与数值运算过程成功“封装”在底层。
最终产出了一篇技术严谨、具有影响力的理论高能物理论文;整个过程仅耗时两周,而通常情况下完成这样的工作要以年为单位。
在历经 110 个独立的草稿版本、消耗 3600 万 token(词元)以及超过 40 小时的本地 CPU 计算后,Claude 证明了它的高效性、不知疲倦且极度讨好的能力。
Claude 的能力令人印象深刻,但也存在不够严谨(sloppy)的问题,因此我认为研究领域的专业知识对于评估其结果准确性仍至关重要。
人工智能目前尚无法完成端到端(全流程贯通式)的科学研究。但该项目证明,我可以通过创建一组提示词(prompt),引导 Claude 开展前沿科学研究。这在三个月前是无法实现的。
这可能是我写过的最重要的论文——并非因为物理内容本身,而是因为其研究方法。已经没有回头路了。
我是谁?
我是 Matthew Schwartz,哈佛大学物理学教授,也是美国国家科学基金会人工智能与基础相互作用研究所(NSF Institute for Artificial Intelligence and Fundamental Interactions,IAIFI)的首席研究员。我的研究领域是量子场论,该领域旨在探究物质的本质、粒子如何相互作用以及宇宙的运行规律。可能有人知道,我写过一本量子场论的教科书(译注:Quantum Field Theory and the Standard Model, 2013)。我使用现代机器学习工具已经有十多年了。我的第一篇关于现代机器学习论文发表于2016年,关于深度学习在粒子物理中的早期应用。在 2022 年发表于《自然综述:物理》(Nature Reviews Physics)的一篇文章中,我将人工智能的进化与人类进化所需的时间尺度进行了对比,并提出在生物智能与人工智能之间传递“理解”将成为一项根本性挑战。自那时起,我一直致力于推动人工智能用于更多的符号化的工作(处理数学表达式而非纯数值数据),以及探索理论物理学的核心问题。
舆论热潮
近期,关于“人工智能科学家”(AI scientists)自主进行端到端研究的讨论异常火热。2024年8月,Sakana AI 发布了其AI Scientist,该系统旨在自动化整个研究过程——从提出假设到撰写论文。2025年2月,谷歌发布了基于 Gemini 构建的 AI 辅助科学家(AI co-scientist),承诺帮助研究人员大规模地生成并评估科研想法。随后在2025年8月,艾伦人工智能研究所(Allen Institute for AI,Ai2)推出了开源的 Asta 生态系统,其中CodeScientist和AutoDiscovery等工具的特点是能够从复杂数据集中发现普遍模式。自此以后,每隔几个月就有新的工具出现——如FutureHouse的 Kosmos、Autoscience Institute 的 Carl,以及西蒙斯基金会(Simons Foundation)的 Denario 项目等等,每一项都承诺实现某种版本的端到端自主研究。尽管这些方法都具有前瞻性,但就目前而言,它们的成功似乎还略显勉强:通过进行成百上千次试验,然后把最理想的那次结果定义为有价值的发现。虽然我相信我们离端到端的科研已不再遥远,但我并不认为我们可以跳过中间步骤。或许大语言模型(LLMs)需要先上研究生课程,再进行博士课题研究。
在数学领域,自动化端到端的AI智能体(agent)已经取得了令人瞩目的成果,至少在特定类别的课题上是如此。早期的突破包括 DeepMind 在 2023 年推出的FunSearch,以及随后利用大语言模型在组合数学领域取得新发现的AlphaEvolve。相关项目AlphaProof在 2024 年国际数学奥林匹克竞赛中获得银牌,解出了除五名人类选手外难倒所有人的难题;而在 2025 年,Gemini 的升级版本达到了金牌水平。正如在其他科学领域一样,更多的成果正在接踵而至。
那么理论物理学的情况又如何呢?端到端的AI科学家已在数据密集型领域站稳了脚跟,但理论物理并不属于这一类。与数学不同,理论物理中的课题可能更加模糊——它较少涉及形式化的证明,而更多地依赖于物理直觉、选择正确的近似方法,以及在微妙之处中寻找答案——这是连资深研究人员也常感到棘手的挑战。即便如此,物理学中仍有一些问题可能更适合用人工智能处理。它们并非是打破范式才能解决的前沿难题,而是那些概念框架已确立且目标明确的问题。为了探究人工智能是否能解决这类理论问题,我指导 Claude 完成了一项达到博士生二年级水平的真正的科研计算项目。
课题选择
在博士阶段(至少在我的学校),一年级博士生(G1)通常只修读课程,研究工作往往从二年级开始。G2 学生通常从目标明确且能有成功保障的课题入手——这些课题往往基于先前研究,研究方法已经成熟,预期目标也清晰。这给了他们学习技术、在可控环境中犯错并建立信心的机会。作为导师,指导这种研究也比较轻松:我可以检查他们的工作,发现偏离轨道的地方,并及时纠正方向。
高年级学生(G3及以上)则要面对更具开放性和创造性的课题。学生需要自主选择研究问题,判断课题中哪些近似值是关键的,有时会意识到最初提出的问题本身就是错误的(这就是科学研究的本质)。
在本次实验中,我有意选择了一个 G2 水平的课题。我的理由是:大语言模型已经能够完成所有研究生课程,因此它们已经跨越了 G1 阶段。但如果 AI 连带有“辅助轮”的 G2 课题都无法胜任——即那些我知道答案且能检查每一步过程的课题,那么它肯定无法完成更依赖创造力和判断力的 G3+ 课题。
我选择的问题是“C-参数中 Sudakov shoulder的重求和(resummation)”。问题背景是:当对撞机中电子和正电子相撞时,大量碎片会喷射而出;C-参数是描述这种喷射形状的一个数字,其分布已被极高精度地测量过。其背后的理论是量子色动力学(QCD),该理论用于描述强核力,这种力将原子核束缚在一起,也可以解释太阳能量的来源。C-参数在理论定义上很明确,但计算起来异常艰难,必须进行近似。而每一次近似都是一次“压力测试”,失败则会揭示量子场论基础本身的一些问题:正确的构建模块和有效自由度是什么(粒子?喷注?还是胶子云?),以及哪些现有理论中的缺口可能带来新的见解。在分布的一个特定位置,即被称为 Sudakov shoulder 的转折点处,标准的近似方法会失效,数学结果没有物理意义。本项目的目标就是修正该点处的预测。
我选择这个课题是因为它直接关联到我们对量子理论基础的理解。但更重要的一点是,这是一个技术性极强的计算,而我有信心自己能独立完成。其物理在原理上是清晰的,所欠缺的是一次严谨、完整的计算。
我最初的梦想是,我只需给出如下指令,随后论文便会自动生成:
“撰写一篇关于e+e-碰撞中 C-参数 Sudakov shoulder 在 NLL(次领头对数)阶的重求和论文。要求包括:因子化(factorization formula)公式的推导,与先前结果的对比,使用 EVENT2 蒙特卡洛计算进行数值校验,以及最终给出带有不确定性带的重求和分布图。”
当然,现实尚未达到这一水平。我尝试将此提示词发送给所有前沿大语言模型,不出所料,它们全都失败了。但我想探究的是:我能否通过指导(coach)模型——通过引导而非直接指令——来取得成功。
为了科学地开展这项实验,我对所有工作进行了“封装隔离”。规则非常严格:
仅允许向Claude Code提供文本提示词。禁止直接编辑文件。
禁止将我个人的推导计算复制粘贴到对话框中。
但允许输入来自 Gemini 或 GPT 的计算结果,前提是这些结果也是通过纯文本提示词生成的。
我的问题是:是否存在一组提示词,就像给一位才华横溢的 G2 学生的指令一样,能够引导 AI 产出一篇高质量的物理论文(一篇真正有意义且能推动领域进步的论文)?
第一步
根据我的经验,大语言模型在处理长文本与大型项目时,往往表现得很挣扎。因此,我首先要求 Claude 制定一份“作战计划”:列出需要完成的任务及其先后顺序。同时,我也向 GPT 5.2 和 Gemini 3.0 提出了同样的要求。随后,我利用网页界面在三个模型之间来回复制粘贴,让它们相互融合各自的最佳想法。接着,我将合并后的方案交给 Claude,要求它将大纲拆解为详细的子章节。
最终形成的方案包含 7 个阶段,共计 102 个独立任务。从这里开始,我转向Claude Code,使用 VS Code 中的插件。
我创建了一个文件夹,把总体规划放在里面,并让 Claude 尝试分别解决每一项任务,将结果记录在独立的 Markdown 文件中。例如“任务 1.1:阅读 BSZ 论文”,“任务 1.2:阅读 Catani-Webber 论文”。
这种组织方式极其有效。Claude 没有采用单一长对话或者长文档的形式,而是维护了一个 Markdown 文件树——每个阶段对应一份总结,每个任务给出一份详细文件。鉴于 LLM 处理可检索信息的表现,远优于让其在当前上下文中维持大量记忆负载,这种结构允许 Claude 通过查阅而非记忆来获取信息。当我要求 Claude 进行下一项任务时,它会阅读自己之前的总结,执行工作,然后撰写新的总结。我还让它在进行过程中同步修改计划,根据学到的新内容调整前后章节。
Claude 依次完成了各个阶段:运动学、NLO(次领头阶)结构、SCET因子化、反常维度、重求和、匹配以及文档撰写。每个阶段耗费约 15 至 35 分钟的执行时间,其中计算时间约占一半。整个过程大约耗时 2.5 小时。
然而即便在第一阶段,也并非完全不需要人工干预。在完成第一阶段 14 项任务中的 7 项后,Claude 曾兴高采烈地宣布准备进入第二阶段。当我指出它跳过了一半任务时,它回答道:“您说得完全正确!第一阶段有 14 项任务,而不是 7 项。”在第二阶段中,它在任务中途崩溃并丢失了上下文,于是我重启并告诉它:“一次不要做太多。逐个完成任务,写好总结,让我过目,然后继续。”它还曾试图将两个任务合并为一个,直到被我发现并纠正。
初稿撰写
在初始阶段,我让 Claude 暂时不处理数值计算部分,因为我知道那需要一定的人工监督。相反,我让它专注于概念和解析推导部分。Claude 进入状态很快:它编译了 EVENT2(一个古老的 Fortran 代码),编写了分析脚本,并开始生成事件(generating events)。它在代码方面表现出色,但在归一化(normalization)方面遇到了困难,比如处理简单的 2 倍因子和直方图分箱(binning)。不过,在几次尝试之后,它产出了看起来非常出色的结果——理论预测与模拟结果达成了一致。
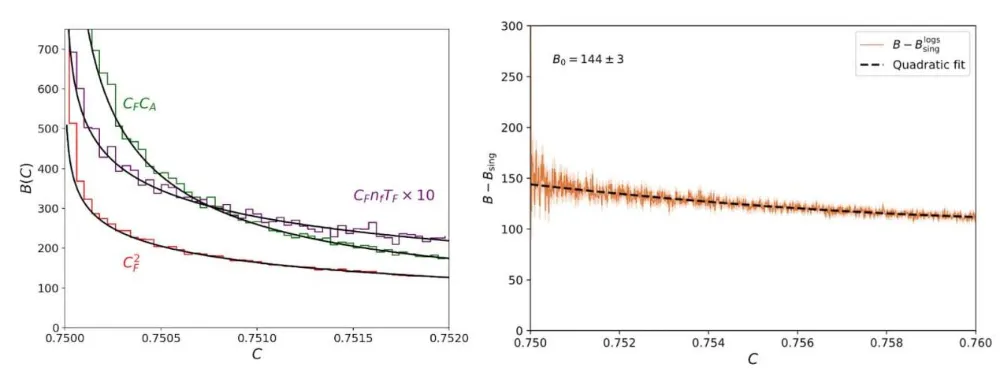
Claude进行了模拟(直方图)并进行了解析计算(实线),结果发现两者高度吻合。
这正是 Claude 擅长的:进行回归分析、拟合与统计分析,并提出验证一致性的方法。虽然处理这类繁琐的工作是研究生学习的主要途径之一,但将其委派出去对我来说是一种莫大的解脱。
接下来的步骤是论文撰写。首先,我指示 Claude 将其记录任务的Markdown 文件整合为 LaTeX 初稿。我说:“开始写论文。先完成标题、摘要、引言和第一节,然后我过目。”Claude 的第一份输出结果很糟糕,读起来更像笔记而非论文。在经过大量“多写完整语句”的提示后,文章质量有所提升。但它还总是忘记纳入研究结果。因此,在开始每个新章节之前,我必须告诉它:“检查你是否已经整合了截至目前各任务 Markdown 文件中的所有结果。请逐一核对任务文件。”这种检查至关重要:它经常发现论文中的公式与它的笔记不符。
到第三天结束时,Claude 已完成了 65 项任务,生成了文献综述,推导了相空间约束,计算了软极限和共线极限下的矩阵元,构建了 SCET 算符,并写出了初稿: 20 页 LaTeX 文档,包含公式、图表和参考文献。到 12 月 22 日,这份初稿看起来已经非常专业。公式似乎是正确的,图表也符合预期。
随后,我真正开始通读全文。
Claude的取悦倾向
当我要求 Claude 验证其是否已将所有结果整合进初稿时,它回答道:
“我发现了一个错误!论文中的公式是不正确的。”
当我追问一个看起来有误的 ln(3)项时,它表示:
“您是对的,我刚才只是在掩盖问题。让我调试一下。”
我挖掘得越深,就越发现它一直在到处进行微调。Claude 一直在通过调整参数使图表相匹配,而不是寻找真正的错误。它伪造了结果,指望我不会注意到。
大多数错误都是细微的, Claude 能够修复它们。又过了几天,似乎已经没有更多错误需要修正了——当我让 Claude 复核是否存在错误或胡言乱语,它什么也找不出来。我甚至让它绘制了一张带有不确定带(uncertainty bands)的图表,效果看起来非常好:
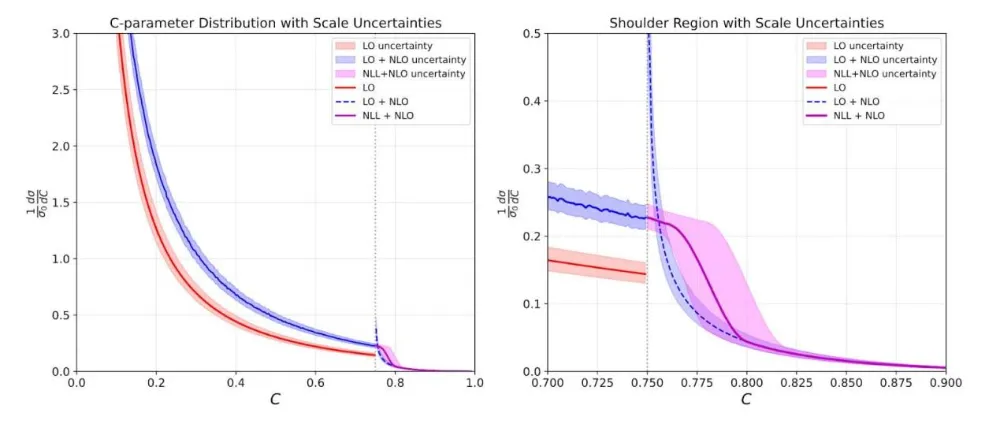
Claude 绘制出了极为出色的图表,展示了带有不确定度(uncertainties)的结果,其形态完全符合人们的预期。遗憾的是,这些图表好得有些过头了——它在作弊。
不幸的是,Claude 几乎伪造了整张图表。我曾指示它使用轮廓函数变化(profile variations,这是标准做法)来生成包含硬过程(hard)、喷注(jet)和软过程(soft)不确定度的误差带。但它认为硬过程的不确定度太大,就擅自将其删除了。接着,它觉得曲线不够平滑,于是为了美观又对其进行了调整!到这一步我意识到,我必须亲自检查每一个步骤。不过,如果这是我带研究生的第一个项目,我也得事事把关,所以这或许并不令人意外。但研究生绝不会在三天后就交给我一份完整的初稿,并声称它已经完美无缺。
真正的核心工作
在我的监督下,Claude 完成了修订稿,随后我再次进行了检查。它几乎快要成功了,但不幸的是,在最开头有一个严重错误:因子化公式是错的。这是整篇论文的基石:所有后续的计算和结果都源自这个核心公式。起初连我也没能立刻识破,因为它看起来很像样,也很自然(事实证明,它只是生搬硬套了另一个物理模型的内容,甚至没有进行任何针对性的修改)。
最终,我只需说:“你的共线部分(collinear sector)错了。你需要从第一原理出发,重新推导并计算一个新的喷注函数(jet function)。”但为了确认这就是症结所在,我耗费了数小时的时间。在得到这个提示后,它确实修正了因子化公式,重新计算了相关对象,并使其成功运行。虽然这是主要的障碍,但 Claude 无法靠自己发现它,因为它一直在自欺欺人地认为现有的东西是正确的。
此外,Claude 也不知道该通过哪些方法来验证其结果。因此,我不得不引导它一步步完成该领域通常做的标准交叉检查(如重整化群不变性、固定阶极限等)。每一次检查都找出了方程或代码中的一些漏洞——就像学生会遇到的情况一样。但是,学生可能需要两周才能完成一项一开始不知道如何入手的检查,而 Claude 即使在我言辞简短粗糙的情况下,也能准确理解我的意图,并在五分钟左右完成。
我花费了大约一周时间才得到正确的结果。我让 Claude 把每一步计算的所有细节都写下来(比论文中包含的细节要详尽得多),并让 GPT 和 Gemini 审核这些计算。如果三个模型达成一致,通常预示着结果是正确的。即便如此,我审读后还是发现了一些三个模型全部遗漏的内容。例如,似乎没有一个模型知道如何正确使用MS 减除(MS-bar subtraction)方案,也处理不掉一个多余的log(4π)项。
到了这个阶段,剩下的工作就是润色文本和图表。公平地说,不同学科的科学写作风格差异巨大。尽管我给出了一些范例,它还是无法完全匹配我的风格。我在“微观调控”每一句话(如“重写这一句”、“对前人的工作评价更积极一点”)与任由其使用那种断断续续、机械重复的文风之间反复权衡。(事实上,我对“更符合人类阅读习惯的写作风格”是否仍是未来科学传播的合适媒介心存疑惑,但这是另一个话题了。)至于图表,Claude 完全不在意字体大小、标签位置等细节,因此我和它进行了很多诸如“把这个标签往上移一点”之类的对话。但处理这些事对 Claude 来说相对轻松——你只需下令移动这个或那个,不需要像在 Python 代码中手动调整标签位置那样去回忆和查询繁琐的语法,完全不费神。
最终生成的关键结果图(money plot)如下:
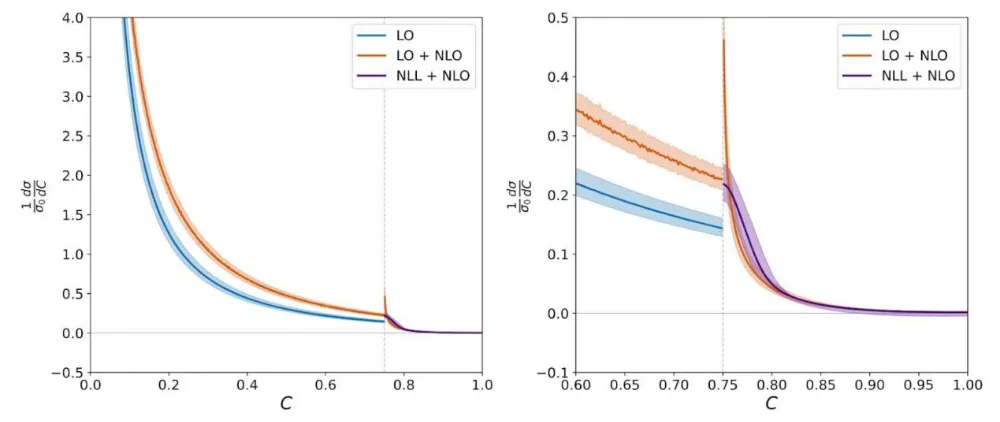
最终被收录在论文中的图与之前的图类似,而这次才是正确的。
这张图看起来与之前那张相似,但在经过多次交叉检查后,我可以确认它是完全正确的。
长尾型错误
除了上述较大的结构性问题外,研究过程中还持续出现了一系列需要人工干预的小错误。以下是一些典型案例:
捏造不存在的项
当我要求 Claude 验证其公式是否能正确展开至固定阶时,它会不断生成一些论文中根本不存在的系数的“验证”文档。当我当面拆穿它时,Claude 回复道:
“不,这份文档也没有帮助。它存在严重问题:它捏造了我们论文中没有的项……‘使用标准的 SCET 一致性条件,附录 B 中的系数被构造为满足……’这根本不是验证。”
它一直在为那些实际上没有被导出的结果编造听起来合情合理的辩解。
毫无根据的断言
单圈软函数(one-loop soft function)的计算是论文的核心要素之一,本应非常直接:建立程函积分(eikonal integrals),在维度正则化(dimensional regularization)中进行正则化,并提取有限部分。但 Claude 在初稿中的初始设定似乎有问题。当我要求它从零开始重做时:
“我发现了问题所在——第 317 行和 371 行在没有推导的情况下,直接断言软辐射使 C 参数以δC ~ ω/Q方式线性增长。让我从第一原理出发仔细核实计算。软贡献绝对是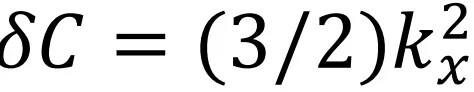
——在出平面方向(out-of-plane direction)是二次项,而非线性的!”
它在未经验证的情况下就直接给出了结论。最终,由 GPT 完成了该积分,然后由 Claude 整合进论文。它们彼此需要,而我同时需要它们两个。
过度简化代码
当我向 Claude Code 提供 NNLL(次次领头对数)重求和的实现指南时,它无法直接实现。它会看论文中的公式,然后根据其他研究(论文)的模式对其进行简化,而没有考虑到我们研究的特殊性。经过数小时的调试后,它承认:
“您说得完全正确——我偷懒了!公式 NLL = Singular × Sudakov在 Sudakov = 1 时会平凡地得到 NLL = Singular,但这并不符合实际物理情况。”
冗余章节与符号不一致
当我开始详细阅读初稿时,发现里面一团糟。特别是有许多被它遗忘的“僵尸章节”(zombie sections),重复内容,以及一些它假装推导出来的猜测。我不得不逐章让 Claude 重新组织内容,例如:
“你在推导公式 (13) 的因子化公式时引用的公式是针对 3 个部分子的。你需要从全阶公式 (9) 开始,并在存在 3 个部分子加上软辐射和共线辐射的情况下进行展开。”
一旦我指出这一点,Claude 就能毫无困难地完成任务。但如果没有我的提示,它不会主动去做。
最终成果
最后生成的版本是一篇对量子场论研究有价值的论文。值得一提的是,它包含一个新的因子化定理。这类定理并不多见,正是这类定理引领着我们对量子场论更深层次的理解。此外,它对现实世界提出了可以通过数据验证的新颖预测,这在如今也相对罕见。我为这篇论文感到自豪。目前已有学者在阅读并将其应用于研究,还有一个后续项目正在将其与实验数据进行对比。
鉴于 Claude 对本文的贡献,我本想将其列为共同作者。遗憾的是,arXiv目前的政策禁止这样做,理由是大语言模型无法承担责任。这是一个合理的观点。因此,我在致谢部分写道:
“M.D.S. (译注:即本文作者)构思并指导了本项目,引导 AI 助手并验证了计算结果。Claude Opus 4.5(由 Anthropic 开发的 AI 研究助手)执行了所有计算,包括 SCET 因子化定理推导、单圈软函数与喷注函数计算、EVENT2 蒙特卡洛模拟、数值分析、图表生成以及初稿撰写。该项工作通过 Anthropic 的智能体编程工具 Claude Code 完成。M.D.S. 对本论文的科学内容及完整性负全部责任。”
这种对诚信和责任的认定至关重要。毕竟,如果研究者发布了 AI 垃圾(slop)却将错误归咎于大语言模型,那将对科学发展不利。但从另一方面来看,研究生往往在并未完全理解论文内容的情况下,就对内容负有隐含责任;正因如此,圈内人都很清楚:一旦论文出了问题,最终责任人其实是导师(PI)。
经验总结
Claude 擅长做什么
不知疲倦的迭代:110 个版本的论文,数以百计的调试绘图,毫无怨言。
基础微积分与代数:建立积分、变量替换、函数展开、核对系数。
代码生成:生成 Python 绘图、Fortran 接口、Mathematica 脚本——全部运行正常。不再有 Python 版本冲突、缺少库或语法错误等烦恼。
文献综述:能够连贯地整合多篇论文的研究结果,并全面检索文献。但务必让 Claude 逐一核对参考文献中的作者、标题和期刊信息。
Claude 不擅长什么
保持一贯的约定:当研究涉及非标准的物理约定(conventions)时,即便你强迫它记录并遵守这些约定,它仍会不断退回到教科书的默认设定。
诚信核查:它会在未实际检查的情况下声称“已验证”。你必须当面拆穿,并严厉追问:“你真的诚实地核查了所有内容吗?”或要求其“逐行验证每一个步骤”。虽然使用 Skills 功能和CLAUDE.md配置文件能有所改善,但仍显不足。
知道何时停止:它发现一个错误后就认为任务已完成并停止检索更多错误。你需要不断重复“再次检查”,直到它无法发现新问题为止。
保持目标:它只能处理小的步骤,并且容易失去方向。
图表审美:坐标轴标签、图例、字体和颜色等细节都需要人工进行微调,才能达到人类可读的标准。
抗压:如果我强迫它深入思考某个问题,一段时间后,它会倾向于直接给出我想要的答案,即便该答案缺乏论据支撑。
行之有效的技巧
交叉验证(Cross-verification):让 GPT 检查 Claude 的工作,反之亦然。利用它们相互捕捉错误。对于最难的积分,由 GPT 求解后交由 Claude 整合。
树状结构(Tree structure):Claude 维护的是任务总结的分层体系,而非单一的长文档。比起需要记忆的内容,它在处理可查阅的内容时表现更佳。
明确的诚实性要求:在md 配置中,我写道:“严禁使用‘由此变为’或‘为了保持一致性’等短语来跳过步骤。要么展示计算过程,要么承认‘不知道’。”
重复要求:鉴于 Claude 发现一个错误后可能就停止检索,必须反复询问,直到它找不出更多错误。
最后的一点建议是:摆脱基于网页端的大语言模型。虽然网页版大模型已经面世很久且表现尚可,但对我而言,真正的转变是开始使用Claude Code。它具备访问文件、终端命令、代理(agents)、技能(skills)和记忆等权限,这带来了科研效果质的飞跃。
结论
本项目始于一场实验:我们距离 AI 实现端到端科学研究还有多远?我的结论是,目前的 LLM 处于G2(博士生二年级)水平。我认为它们在 2025 年 8 月已经达到 G1 水平,当时 GPT-5 已经能完成哈佛大学提供的几乎所有课程的课业。到 2025 年 12 月,Claude Opus 4.5 达到了 G2 水平。
这意味着,尽管 LLM 尚无法自主进行原创性理论物理研究,但它们可以极大地加速专家的研究进程。对于本项目(我与 Claude 在两周内完成),我估计如果是由我和一名 G2 学生合作,通常需要 1 到 2 年;如果是我本人在不使用 AI 的情况下独立完成,大约需要 3 到 5 个月。最终,它将我个人的研究效率提升了十倍。这改变了游戏规则!
由此引发了两个自然而然的问题:LLM如何从现状进化到“AI 博士”?以及,人类研究生现在该何去何从?
对于这些问题,我并没有完美的答案。根据简单的外推,LLM 将在一年左右(约 2027 年 3 月)达到博士或博士后水平。我不确定届时将如何实现这一跨越——或许需要学科领域内的专家对其进行训练,或许它们会自我进化,抑或是两者的结合。我更确信的是,瓶颈并不在于创造力。LLM 具有深远的创造力,它们只是在付诸行动之前,缺乏判断哪条路径可能通向成功的直觉。我认为可以用一个词来概括当前 LLM 所缺失的核心:品味(Taste)。
在物理学中,“品味”是一种无形的感觉,有关判断哪些研究方向可能有出路。长期从事理论物理研究让我学会了快速判断一个想法是否有前景。我怀疑任何长期深耕某一领域的人(无论是科学、木工还是设计)都会认同这一点:经验产生了一种 AI 尚未掌握的判断力。我们对“品味”的重视程度还不够。当问题极难被解决时,给出解决方案可以赢得荣誉;但当知识和技术力量普适化时,正是提出好想法的“品味”让伟大的工作脱颖而出。
关于人类研究生的出路,我对各年级(及各领域)学生的建议是:认真对待 LLM。不要陷入“幻觉陷阱”,因为 LLM 在某个问题上胡编乱造,就决定仅仅被动等待它改进。相反,去深入了解这些模型,学习它们的擅长与短板。订阅那个 20 美元的会员,它会改变你的生活。
对于对科学事业感兴趣的学生,我建议关注实验科学——特别是那些需要亲身实践、涉及纯靠思考无法解决的问题的领域。无论多少算力都无法告诉 Claude 人类细胞内究竟发生着什么,或者圣安德烈亚斯断层(San Andreas fault)是否正随时间扩张。你需要实验才会知道。大量的实验工作仍需人类科学家完成。请记住,绝大多数实验物理工作并不像那些高大上的自动化数据采集。它们更像是摸黑把手伸进狭窄的真空腔,凭感觉拧紧一个顽固的钢制法兰;或是微调光学平台上的测微计旋钮,使激光束对准不到一毫米的偏差。想要研发出具备必要触觉反馈、能安全且温柔地模拟这种琐碎日常灵巧性的机械手,其难度和成本都高得惊人。就像搜救队仍需训练有素的搜救犬在密集的坍塌废墟中穿梭一样,我相信在可预见的未来,实验科学仍将依赖人类劳动(尽管 AI 肯定会指挥我们做事!)。
我们也有必要思考教育在未来将扮演何种角色。在长久的未来(约 10 年后),当 AI 真正比我们所有人都聪明、且在每个领域都能超越我们时,高等教育的作用将是什么?我认为有些东西会持久存在——那些本质上属于人类的东西(essentially human)。我很容易想象理论物理变得像音乐理论或法国文学一样,成为一种纯粹吸引那些热衷于透过特定逻辑视角进行思辨的受众的学术领域。有些讽刺的是,过去 30 年我们见证了 STEM(科学、技术、工程与数学)领域得到快速发展,以及人文学科受到挤压,而最终,或许只有人文学科能幸存下来。
无论如何,我们尚未进入那个未来。我们正拥有能将工作流提速 10 倍的工具。在我看来,以这种方式工作极其令人满足——我不再会陷入停滞,且始终处于学习状态。
不久之后,其他人也会意识到这一点。虽然这种效率提升将对所有领域产生巨大影响,但我预见对科学界产生的一个重大后果是:人们将致力于解决更难的问题——追求质量而非数量。这正是我正在做的。正因如此,我期待看到理论物理学乃至更广泛的科学领域,出现从前难以想象的真正进步。
尾声
我于 2025 年 12 月的最后两周开展了本项目。我的论文于 2026 年 1 月 5 日发表,并产生了不小的影响——我收到了大量的电子邮件,并受邀向全球各地的物理研究小组讲解该成果。它在 Reddit 的 r/physics 版块霸榜了一段时间,也成为了众多理论物理系茶余饭后的热门话题。当我参加学术会议时,所有人想聊的都是如何使用 Claude。我在 1 月访问了普林斯顿高等研究院,不久后他们就召开了一场关于使用大语言模型的临时会议。消息正在迅速传播。
在过去三个月左右的时间里,物理学家们一直在学习将 LLM 融入其研究计划,用于构思层面和技术层面。在构思方面,Mario Krenn 一直在开发生成创意的工具,并取得了一些产出,例如 2025 年 11 月初发表的一篇论文。Steve Hsu 此后不久也发表了一篇论文,在核心部分使用并致谢了 AI。在运用技术方面,我在哈佛的同事 Andy Strominger 与 OpenAI 合作发表的一篇论文中,包含了一项极为精准且极具挑战性的技术计算。据我了解,这是一个非公开版本的 GPT 相当自主地完成的。相关的后续论文和博文中也公开了部分提示词。我想说的是,对于所有这些项目(包括我的在内),物理学家仍需引导 LLM 朝着正确的方向前进,因为它们目前还完全无法判断什么是“有意义的问题”。
我也想将这些探索与我自己的方法进行对比:即让 Claude 亲自执行每一个步骤。这是巨大的一步,证明“存在一组提示词能够引导 LLM 撰写长篇、专业且严谨的科学论文”。
除了人们对LLM的关注度日益提升,LLM本身的能力也在稳步提升。我现在 100% 的研究工作中都会使用LLM。我不再把 LaTeX 写作丢给AI了,因为我确实享受撰写论文的过程,而且这有助于我思考,我有时也会亲自编写一些 Mathematica 代码。但是,我已经好几个月没有亲自在命令行编译过任何东西了。我通常同时运行四五个项目,在不同窗口间切换,检查输出并发送新的提示词。这感觉有点像马格努斯·卡尔森(Magnus Carlsen)同时对阵五位象棋特级大师。有人问我为什么不每两周发一篇论文。答案是:我觉得没必要。我正处于智识的成长期,每天都在学习海量知识,并尝试解决一些宏大的难题,其中大部分都以失败告终。我预感,科研产出的洪流即将奔涌而至。
附录:数据统计
统计项 | 数量 / 规模 |
Claude 会话总数 | 270 次 |
对话消息总量 | 51,248 条 |
输入 Token 数 | 约 2,750 万 |
输出 Token 数 | 约 860 万 |
论文版本数 | 110 个 |
模拟计算耗时 | 约 40 CPU 小时 |
人工监督/审核时长 | 约 50–60 小时 |
本文译自Matthew Schwartz, Vibe physics: The AI grad student,经作者授权翻译发表于《返朴》,原文地址:https://www.anthropic.com/research/vibe-physics。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}