阅读:0
听报道
一阶谓词逻辑、概率论、计算理论等规范性理论模型并不是为了解释人类智能、认知、思维、意识等现象而建立的,为什么要理所当然地把它们作为普适的规范性模型——或者说 “理性”—— 的一般标准呢?
撰文 | 王培(美国天普大学计算机与信息科学系)
“人是理性的动物,但却常常做非理性的事”,这种貌似矛盾的说法差不多算是老生常谈了。本文不是要语出惊人地唱反调,只是想讨论一下,“理性” 的标准是什么,而理性动物们怎么就做出非理性的事来了?
理性这个话题可以算源远流长了。开始是个哲学论题,后面逻辑学、心理学也加入进来,直到成为经济学等社会科学的基本概念,而到我这里,自然最后还是会拉到人工智能的设计问题上来。
心理学从总体上说是描述性的理论,其目标是发现人类心理活动的规律性。但是,心理学在研究推理和判断这样的心理活动时,与规范性的理论发生了密切联系,而后者来自于数学、逻辑学、决策论、博弈论、伦理学等学科和领域,其目标是确定 “人应该怎么做才对”。一类常见的心理学研究是把一个描述性模型(人实际上如何推理和判断)和一个规范性模型(人应当如何推理和判断)相比较。如果二者相符,那么人在这个方面的行为就算是理性的,否则就算是非理性的。
下面让我们分析心理学中两个最常被用来显示非理性行为的例子。有兴趣的读者可以先根据自己的自然反应回答这两个问题,然后看看自己的答案是否也在非理性之列。
“选择任务”
桌上有四张卡片,上面分别标有D,K,3,7。
这些卡片都是一面标有字母,而另一面标有数字的。
你的任务是:翻动最少的卡片,来确定下面“普遍规律”的真假:
“如果一张卡片的一面是D,则另一面就是3”
这个简单实验是心理学家Peter Wason五十多年前设计的,一般被称为“华生选择任务” 或 “四卡问题”(the Four-Card Problem)。这个实验及其各种变体(如修改卡片上的标记)已经在世界各地的不同人群中被重复多次,其结果相当一致。当然,不同的人表现不同(比如有人把所有的卡片都翻过来检查,也有人随便翻),但总的说来,被翻最多的是标着D的那张,其次是3,再次是7,最少的是K。
根据目前公认的 “经典逻辑”(一阶谓词逻辑),上述待验证规律可以严格表述为全称命题:“对论域中的每个对象而言,如果它是一面标有D的卡片,则其另一面一定标着3”。
既然这一规律的描述对象只有那四张卡片,那么只要其中有一张不满足此描述,命题就不成立(为假),否则命题成立(为真)。很显然,D卡片的另一面如果不是3,则该卡片为反例,命题为假,其它卡片就不用翻了。如果D卡片的另一面的确是3,那说明此命题对该卡片成立,即该卡片为正例。
但既然全称命题说的是 “每个对象”,那么找到个正例仍无法确定命题的普遍有效性,所以还要查下去。
类似地,如果3卡片的另一面是D,即该卡片构成正例,否则(比如另一面是A),则其既非正例又非反例(因为它根本不是一面标有D的卡片),因此,无论3卡片的另一面是什么,对确定此全称命题的真假均无贡献。而7卡片的另一面如果是D,它就构成了命题的一个反例,否则与命题无关。最后,不管K卡片的另一面是什么数字,都和此命题的真值无关。
综上所述,此问题的正确答案(根据一阶谓词逻辑)是选择翻动标有D和7的卡片——以检查它们是否构成所考察命题的反例,找到一个就够了,而不动那两张标有K和3的卡片。
你答对了吗?
一般而言,普遍性结论在一阶谓词逻辑中被表述成全称命题,其真值完全取决于是否存在反例,而与正例的存在与否或多寡无关。
但是,在面对此类问题时,人们往往对正例更关注,却不那么关注反例,这是 “不合逻辑的”,自然也就被判定为 “非理性行为” 了。

心理学家Peter Wason(1924-2003)在伦敦海格特公墓(Highgate Cemetery)的墓碑。墓碑下方刻着他设计的选择任务,也称为“四卡问题”。来源:wikipedia
“合取谬误”
当结论不是非真即假,而是有不同程度的不确定性(或者说正确性、可能性)时,目前公认的规范性推理和决策模型是基于概率论的。这是因为,在很多实际问题的解决过程中,概率论已经大显身手,更重要的是,人们已经证明,违反概率论会导致不良后果(比如陷入必输的赌局)。
不过,心理学家们多年来进行了大量的实验,取得的结果已经充分说明,人类的推理和判断显著不同于(不符合)概率论的要求。在这些研究中,影响最大的当推Amos Tversky 和 Daniel Kahneman的研究。下面就是他们给出的一个例子:
琳达是个31岁的单身女性。她说话直率而且非常聪明。她在大学时主修哲学,那时她就对歧视和社会公正等问题深感关切,而且参加了反核游行。
下面哪句话成立的可能性更大:
(A)琳达是个银行柜员。
(B)琳达是个银行柜员,而且还是个女权运动积极分子。
实验结果表明,大部分人会选B,但B要求琳达同时符合两个条件(逻辑上叫做“合取”),而A只要求其中之一。根据概率论,任何东西同时符合两个条件的概率不可能大于只符合其中一个的概率。这就是说,大部分人在这类问题上都违反了概率论。既然概率论代表着理性,人的这种选择就是非理性的了。这就是所谓 “合取谬误”, 又称 “琳达问题”。
Tversky 和 Kahneman提出的解释是,人们常常把 “代表性” 误认为概率(即事件的发生可能)。当对琳达的描述符合人们对 “女权运动积极分子” 的印象时,人们就倾向于断言她不仅仅是个银行柜员,而没有考虑到增加了一个条件反而会降低结论的成立可能。
谁错了?
既然有确切证据表明人类思维活动在某些方面不符合作为理性标准的规范性模型,那我们似乎就应该承认这种缺陷,并尽量设法避免其不良后果,这是目前学术界的主流意见,Kahneman也因相关工作获得了2002年的诺贝尔经济学奖(Tversky已于1996年去世)。
但也有少数人不认同这个结论。既然人类思维规律是长期进化的结果,怎么会有这么大的缺陷?会不会是那些规范性模型错了?
这听上去像是讳疾忌医,因为用逻辑和概率论推出的结论应该比人的直观判断可靠多了。但这事还真没这么简单。像我在《面对复杂现象,怎样找个靠谱的解释?| AI那厮》一文中所说的,对同一个现象往往可以找到多种解释。有些研究者不认为上述心理实验结果能说明“人是非理性的”,因为他们对这些结果给出了不同的解释。在本文中,我不打算逐个介绍这些解释(因为实在太多了),而只想谈谈我的看法。
我曾说过,每个规范性模型都是以某些 “公理” 或 “公设” 为前提条件的(详见《能否用数学确定美国大选是否舞弊?| AI那厮》)。
但是,这些前提尽管看起来很有道理,却不是对任何情景都适用的。如果在前提条件未被满足的情况下使用一个模型,其结论就失去了其规范性,也就未必是理性的了。
一阶谓词逻辑作为数理逻辑的核心,是按照数学中定理证明的要求所设计的,而一个命题被证明为定理的必要条件之一,就是不能有反例。因此,在这种逻辑中,把 “真“ 看作 ”没有反例” 是完全合理的,而是否有正例完全不影响一个全称命题的真值。
比如说在华生选择任务中,命题 “如果卡片的一面是空白的,则另一面是3” 就是真的,因为所有卡片都不满足条件,因此这个 “规律” 就没有反例。这个结果与很多人的直觉相反(这是所谓 “蕴涵怪论” 的体现,在此不细谈)。
在经验科学和日常生活中,当我们评价一个结论的真假时,通常正、反例都是要考虑的,而一个 “正确” 的结论应该正例多而反例少(当然没有反例更好),也就是说起码要 “在通常情况下成立”。此时,人们通常不会因个别反例的存在而抛弃一个理论,而是会去寻找“化解” 反例的方法(比如重新解释观察,添加辅助假设等等)——这和在数学中的情形截然不同。
这就是我对华生选择任务的解释:大部分被试表现出寻找正例的倾向,因为在他们的日常推理活动中,结论是否正确,与正、反例都相关,而且正例比反例更容易识别。当然,这不是说在这类问题上人就不会犯错误。在选择任务的某些版本中,题目摆明了是要找反例,比如说,如果要确定一间酒吧中是否有未达到法定年龄的饮酒者,那么该查的是一个少年在喝什么和一个饮酒者的年龄,而非一位老人在喝什么或一个喝果汁的人的年龄。
“琳达问题” 则涉及概念的刻画方式。概率论的通常用法是把一个概念看成一个集合,比如 “银行柜员” A和 “女权运动积极分子” B都是 “人” 这个集合C的子集,而 “琳达” (作为一个人)属于A或B的概率分别是A和B相对于C的大小。“是银行柜员又是女权运动积极分子的人” (下图中的深紫色部分)显然是 A 和 B 的公共子集,因此 “琳达” 在其中的概率不可能大于在A中的概率。
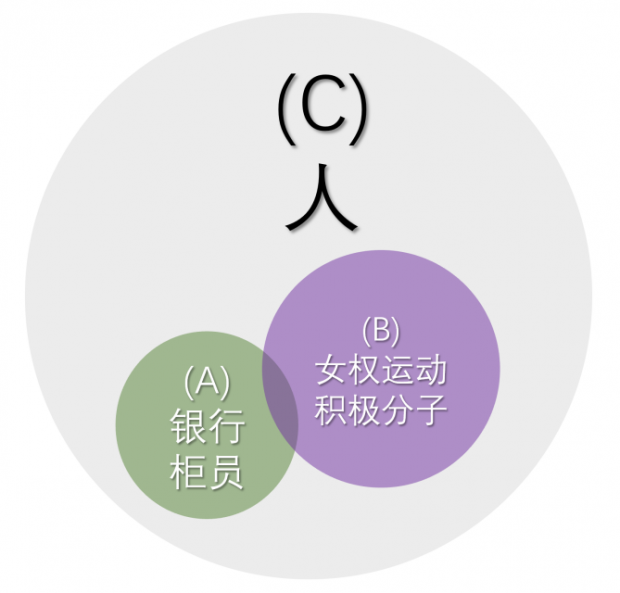
示意图:ABC三个集合的关系丨作者作图
这个常见论证有两个前提:(1)一个概念是完全由其外延来界定的,比如说 “银行柜员” 的含义仅仅由这个群体所包含的个体来确定;(2)一个个体属于一个概念的程度是概率,取决于概念外延在个体域中的相对大小。
尽管上述用法在这类问题上司空见惯,但从认知科学的角度来看,还是颇有可以商榷之处的。
在人类的认知中,一个日常概念的意义往往由其内涵来界定。比如说, “女权运动积极分子” 的内涵就是这个概念的成员的共同属性,这些属性可以为概念中大多数成员或典型成员所具有,而不必是每个成员都有。
当我们使用一个概念的内涵来判断某对象是否属于此概念时,其中的属性为这个隶属关系提供了(正、反面)证据,以此确定隶属关系的成立程度。比如说,对琳达的描述和 “银行柜员” 的吻合程度就低于和 “女权运动积极分子” 的吻合程度,而这个吻合程度就是 Tversky 和 Kahneman 所说的 “代表性”。人们常常用这个“代表性”来判断 “琳达是银行柜员” 的真实程度。
由于内涵和外延的反比关系,琳达和 “是银行柜员又是女权运动积极分子” 的吻合程度会高于和 “银行柜员” 的吻合程度,这就解释了这类实验的结果:在判断隶属关系时,概率论用的是概念的外延,而人们往往用概念的内涵。尽管前者的确是更加成熟的规范性模型,但也没有理由把后者判为 “非理性”,因为内涵性判断自有其认知价值。
“那厮”何去何从
根据以上分析,人类推理、判断的行为不完全符合传统规范性模型(一阶谓词逻辑和概率论)的要求,其间的很多差异都不该简单归咎于人的 “非理性行为”,更主要的因素是,模型的前提条件和人类思维活动的现实环境不符。心理学家在从其他领域引进规范性模型时,常常只注意到这些模型在原有领域中的成功,并崇尚其为权威,而没有认真考虑其适用范围。
本文的主要目的不是跨界挑心理学的毛病,而是想说明人工智能研究中存在类似的问题。一阶谓词逻辑、概率论、计算理论等规范性理论模型始终在人工智能中起着重要作用,违背这些理论的设计往往被看作离经叛道。问题是,这些理论都不是为了解释能、认知、思维、意识等现象而建立的,为什么要理所当然地把它们作为普适的规范性模型——或者说 “理性”—— 的一般标准呢?
这并不是一个新问题。人工智能的奠基人之一 Herbert Simon(司马贺)就提出了 “有限理性” 的概念,指出不能忽略人在推理和判断活动中所受的现实约束。尽管如此,由于缺乏成熟的替代品,传统的规范性模型仍常常被用在其适用范围之外。很多人只注重为自己的工作找个可靠的理论基础,而不考虑这个理论的前提条件和适用范围。在这个方面,人工智能领域的问题并不比心理学领域少。
我多次撰文介绍过的 “纳思” 系统就是一个建立在更为现实的前提条件下的规范性模型。纳思力图在系统知识和资源不足的情况下适应环境,或者说在 “不知道” 和 “没想到”的时候,仍能找到、构建出最好的应对方案。
因此,纳思体现了一种 “相对理性“ 的原则,就是说, ”理性“ 是相对于系统现有的知识和资源而言的。纳思设计中的具体选择都是在这个原则的指导下做出的。
回到上文的两个例子。纳思中陈述的真值同时取决于正例和反例(详见《证实、证伪、证明、证据:何以为“证”?》),而概念的意义同时取决于外延和内涵(详见《“意思”是什么意思?》)。
这就是说,纳思在面对 “四卡片问题” 和 “琳达问题” 时,其行为也可能像一般人那样不符合一阶谓词逻辑和概率论的要求。这不是因为我们成心要让纳思犯 “类人” 的错误,以使得它更容易冒充人类,而是因为 “相对理性“ 的原则比传统规范性模型背后的 “绝对理性” 更接近进化过程为人类选择的思维规律。由于纳思的有关性质在前面已经写过(见《你这是什么逻辑?》和参考文献),这里就不再重复了。本文的新内容是显示:纳思除了作为一个人工智能模型之外,也可以解释很多人类心理现象,尽管它的设计目标是成为一个智能(不管是人还是计算机)的规范性模型,而非人类智能的描述性模型。
本文并不是要说人类就没有 “非理性“ 的时候,更不是说纳思就不会犯错误,而是说, “对错” 的标准不像初看起来那么简单。
由于知识和资源不足,纳思的很多预测都会被后来的观察证明是错的,但这些预测在当时的确又是最合理的(相对于系统的知识和资源现状而言)。这么说来,在纳思内部,“存在的就是合理的”。即使考虑到情感的作用,也不是“理性”和 “非理性” 在 “轮流执政”(详见《人工智能,让机器也会“感情用事” | AI那厮》)。
当然,“理性程度” 的差别依然存在。有些决策过程相对稳定,可重复,而且事后可以解释;而另一些则是特殊情景下的临机反应,以至于事后无法准确解释当时的推理和判断,只好说 “我当时不知怎么想的就那样做了”。后一种情况一般被当成说“非理性”的,虽然系统可能并不是“搭错了线”(不管是电线还是神经),也没有修改自身的思维规律。在纳思这样的系统中,这两种情况都会出现,只是二者间的差异是程度上的,而不是“理性”和“非理性”两套机制。
总而言之,“理性”和”非理性“ 的实际区分取决于是否(或者说在多大程度上)可以为行为找到理由。即,行为是系统为达到某个目的所采取的手段。这种分析通常会以某个(明确定义的或模糊默认的)规范性模型为依据,但这个模型未必就是经典逻辑或概率论。因此,以往关于人类 “非理性行为” 的很多结论有必要被重新评价,而人工智能系统的设计也应当建立在切实适用的基础之上。
参考文献
[1] Pei Wang, “Heuristics and normative models of judgment under uncertainty”, International Journal of Approximate Reasoning, 14(4):221-235, 1996
[2] Pei Wang, “Wason's cards: what is wrong?”, Proceedings of the Third International Conference on Cognitive Science, Beijing, August 2001
[3] Pei Wang, “The Assumption on Knowledge and Resources in Models of Rationality”, International Journal of Machine Consciousness, 3:193–218, 2011
[4] Ahmed Abdel-Fattah, Tarek R. Besold, Helmar Gust, Ulf Krumnack, Martin Schmidt, Kai-Uwe Kuhnberger, and Pei Wang, "Rationality-guided AGI as cognitive systems", Proceedings of the Annual Meeting of the Cognitive Science Society, Sapporo, August 2012
访问~wangp/Chinese.html,可查阅作者所有科普文章和科普视频。
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}